Browse or search IF4IT for articles below.
Artificial Intelligence
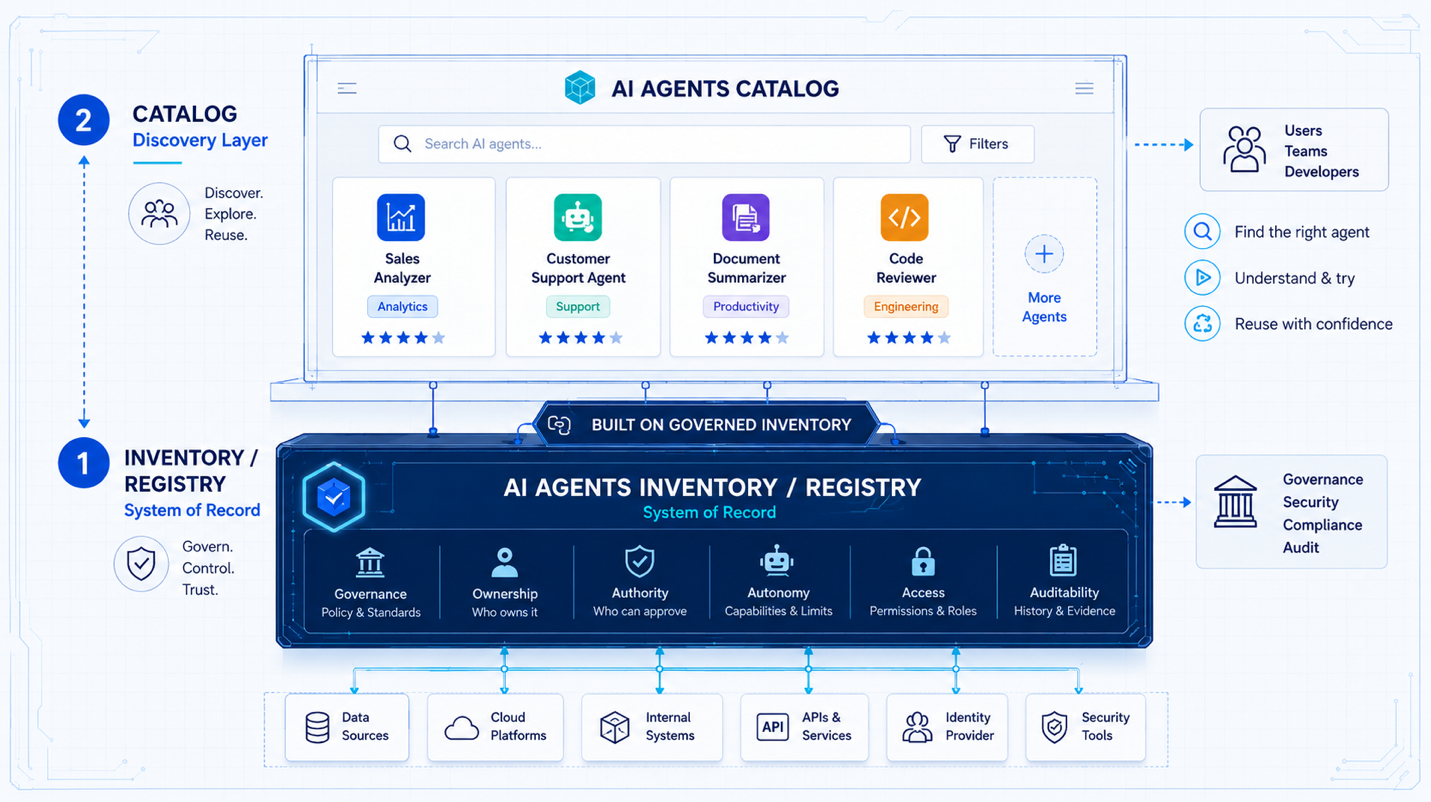
AI Agents Inventory vs. Registry vs. Catalog: What's the Difference?
An AI Agents Inventory and an AI Agents Registry are the same thing: a governed record of the AI agents an enterprise has, who owns them, what they can do, and what they can reach. An AI Agents Catalog is different: it …
read more
AI Exposes the Knowledge Debt Enterprises Can No Longer Ignore
AI is exposing Knowledge Debt: the accumulated loss, fragmentation, and implicit capture of enterprise meaning across systems, data structures, rules, terminology, documentation, and human memory. Making legacy data …
read more
AI Governance Is an Inventory Problem: Why Enterprise AI Governance Starts With an AI Agent Inventory
AI governance is not a new discipline. It is inventory governance applied to a new kind of asset. Enterprises struggling to govern Artificial Intelligence (AI) are usually struggling because they cannot see what AI they …
read more
AI Raises the Stakes on Knowing Yourself as an Enterprise
Artificial intelligence sharply increases the cost of carrying incomplete, stale, fragmented, or contradictory enterprise inventory data because AI systems can turn those defects into confident but unreliable answers. …
read more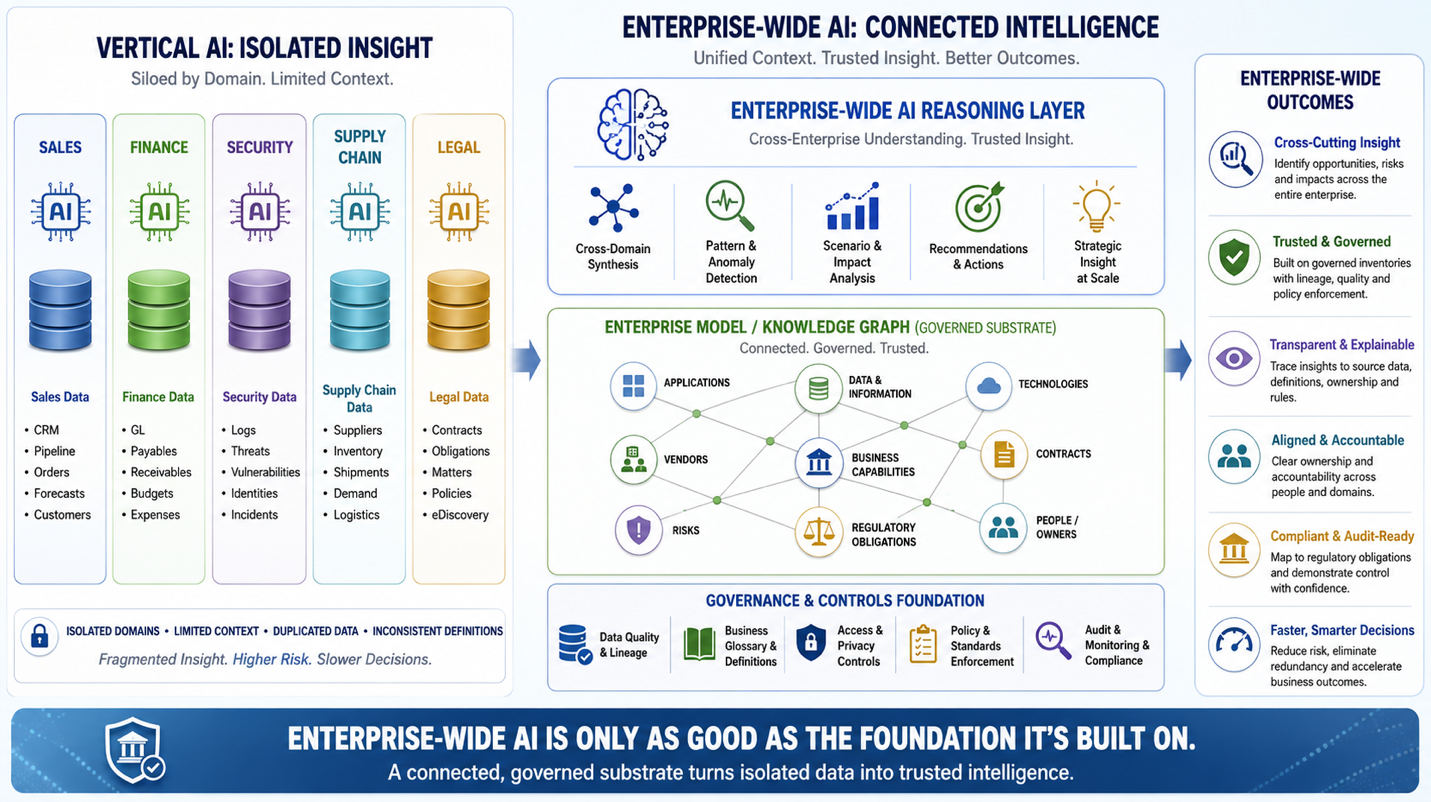
AI Right Isn’t About the Model You Buy — It’s About What You Give It to Reason Over
Enterprise-wide Artificial Intelligence cannot become trustworthy merely by selecting a more capable model. It requires a governed, connected substrate that represents the enterprise across domains. Vertical AI can …
read more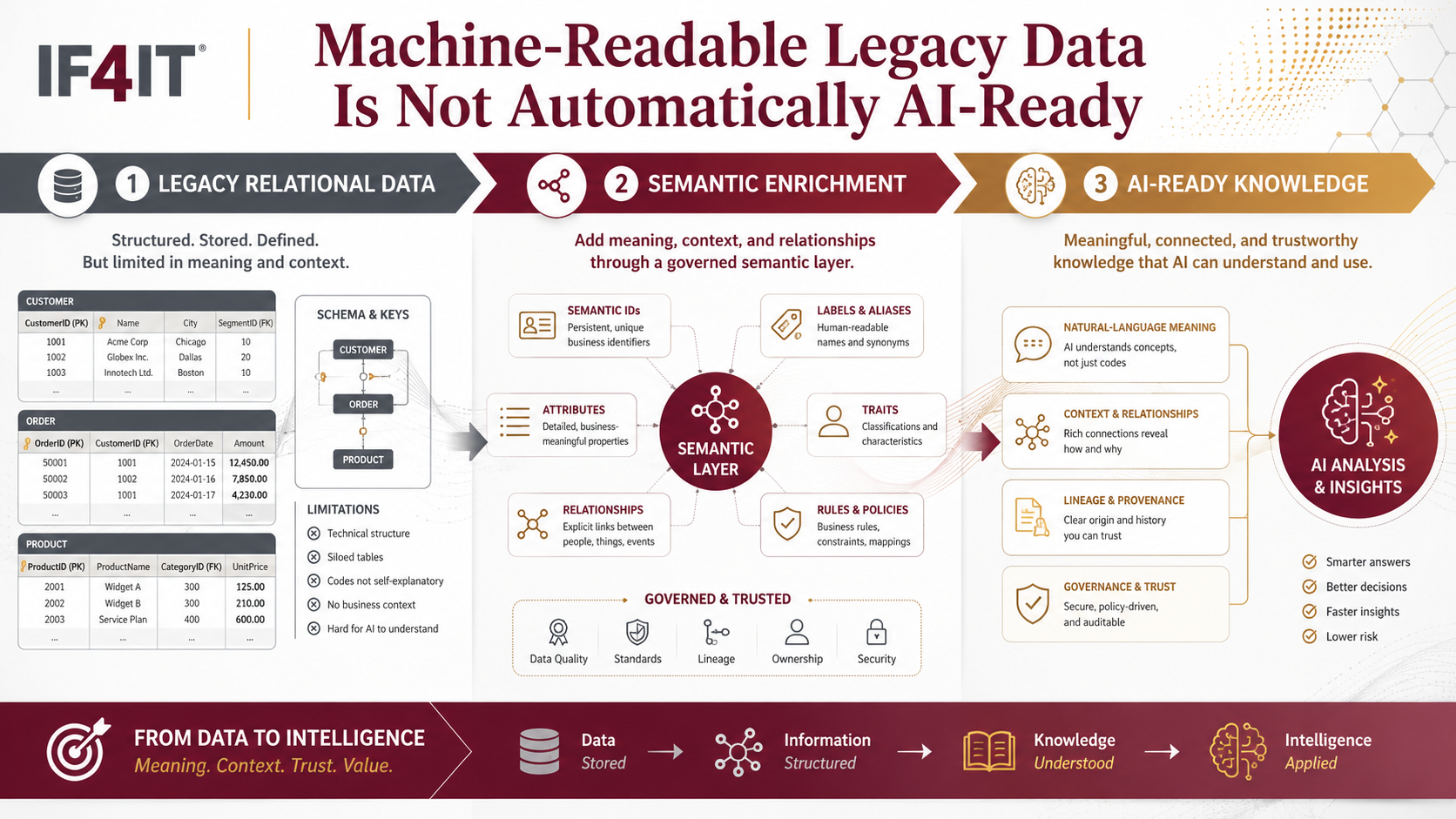
Legacy Data That Is Machine-Readable Is Not Automatically AI-Ready
Machine-readable legacy data is a starting point, not proof that data is ready for AI consumption. Enterprises that simply connect AI to relational tables, APIs, files, or warehouses may give AI access while still …
read more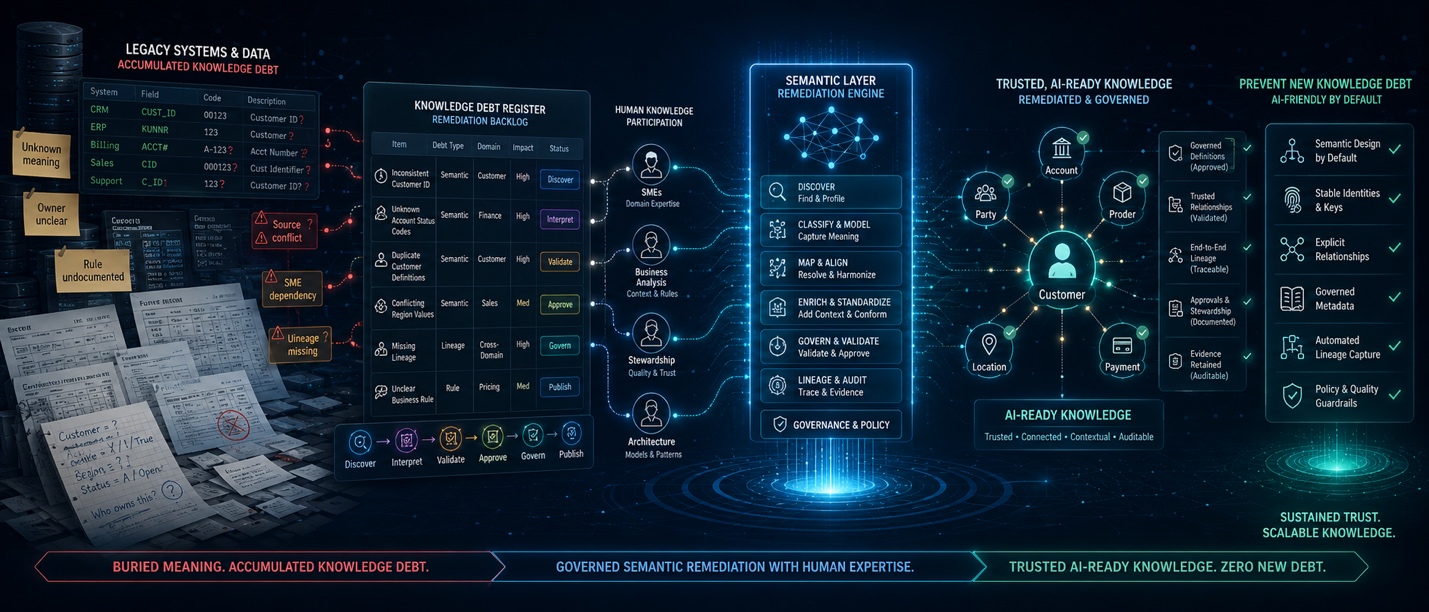
Making Legacy Data AI-Ready Is Knowledge Debt Remediation
Making legacy data semantic and AI-ready is Knowledge Debt remediation: the governed work of making hidden, fragmented, outdated, inconsistent, inaccessible, or poorly governed enterprise meaning explicit. When …
read more
Shadow AI Agents: Why You Can't Govern the Agents You Can't See
Shadow AI agents are AI agents running inside an enterprise that no one has recorded, owns, or governs. They are not a new category of problem; they are the AI form of an old one, the ungoverned asset, and they arise for …
read more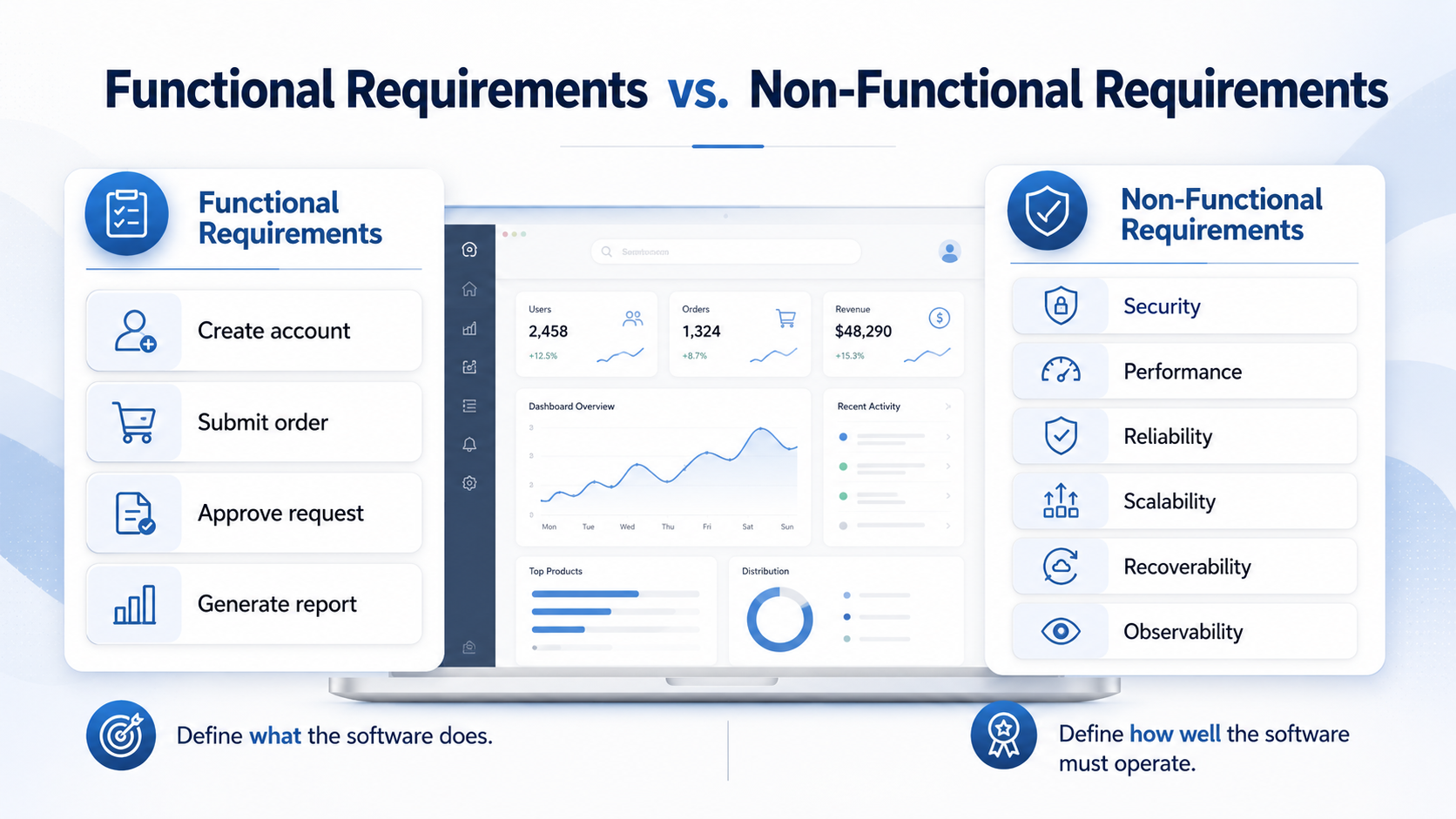
Use Non-Functional Requirements (NFRs) to Expose Critical Gaps in AI Generated Software Like Vibe Code
AI can generate functional software quickly, but software that appears to work may still contain critical gaps in security, performance, resilience, recoverability, operability, and other production qualities. …
read more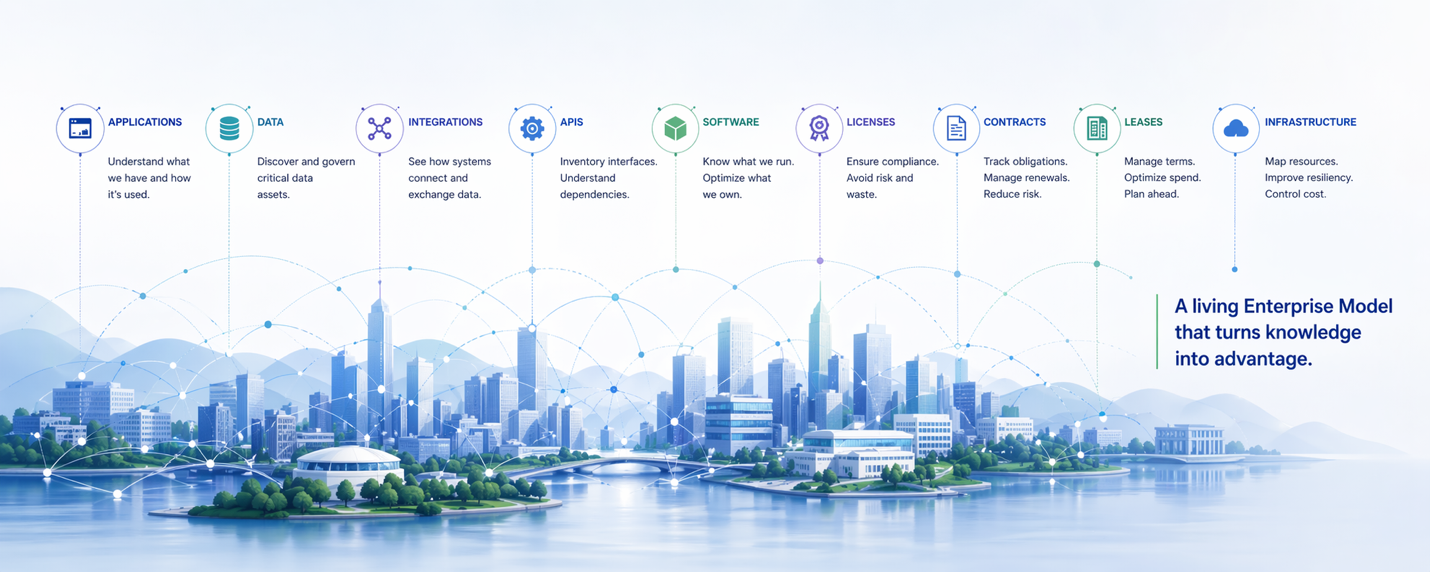
Using AI to Build and Maintain Enterprise Inventories and Models
Artificial intelligence can dramatically reduce the cost, time, and inconsistency involved in building and maintaining enterprise inventories by extracting, reconciling, cleansing, transforming, populating, and relating …
read more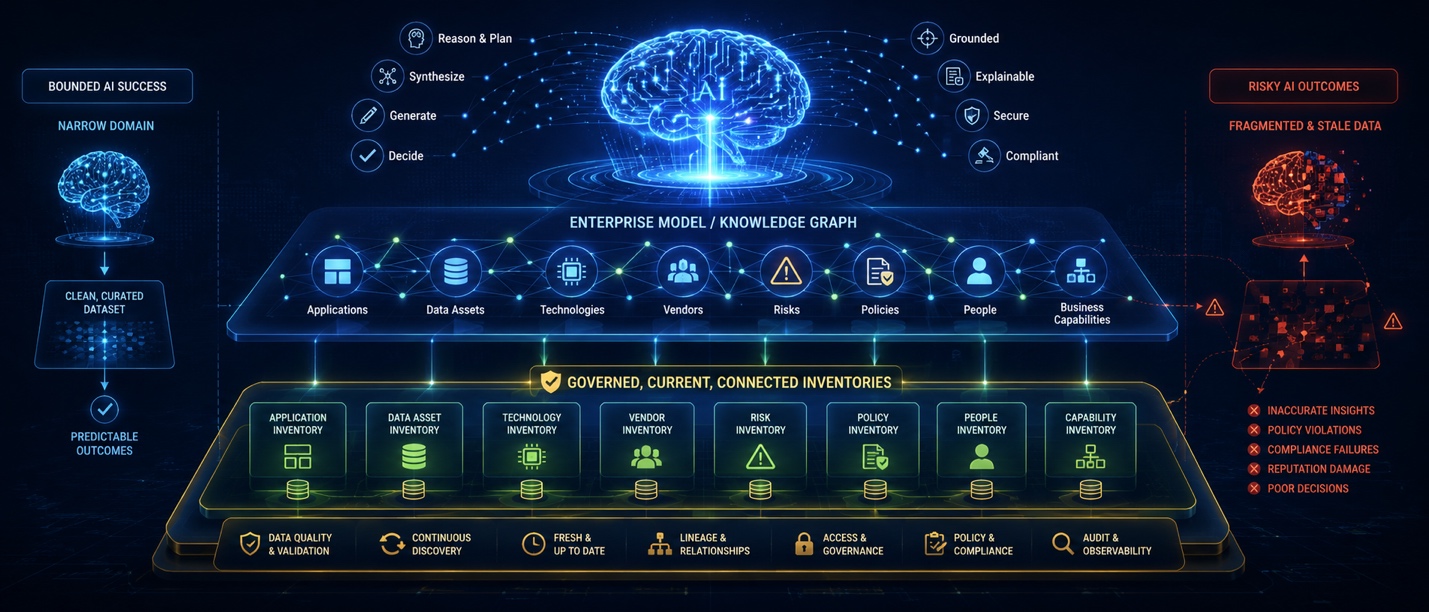
Your Enterprise AI Is Only as Good as Your Enterprise Inventories
Domain-specific AI can succeed with clean, bounded data, but enterprise-spanning AI depends on governed, current, and connected enterprise inventories. Better models, prompts, or retrieval techniques cannot compensate …
read moreAutomation Management
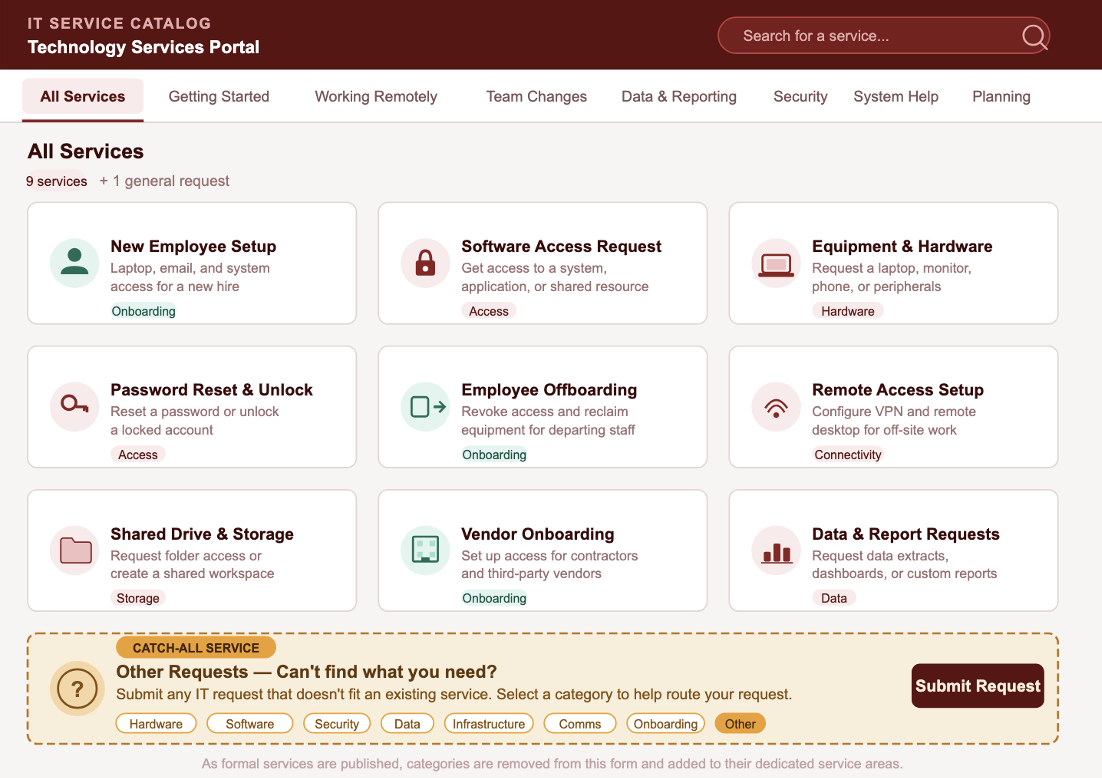
Building Service Catalogs That Actually Work
A service catalog succeeds when business stakeholders can quickly understand what IT can do for them, submit requests through a clear and reliable process, and receive outcomes that match published expectations. …
read more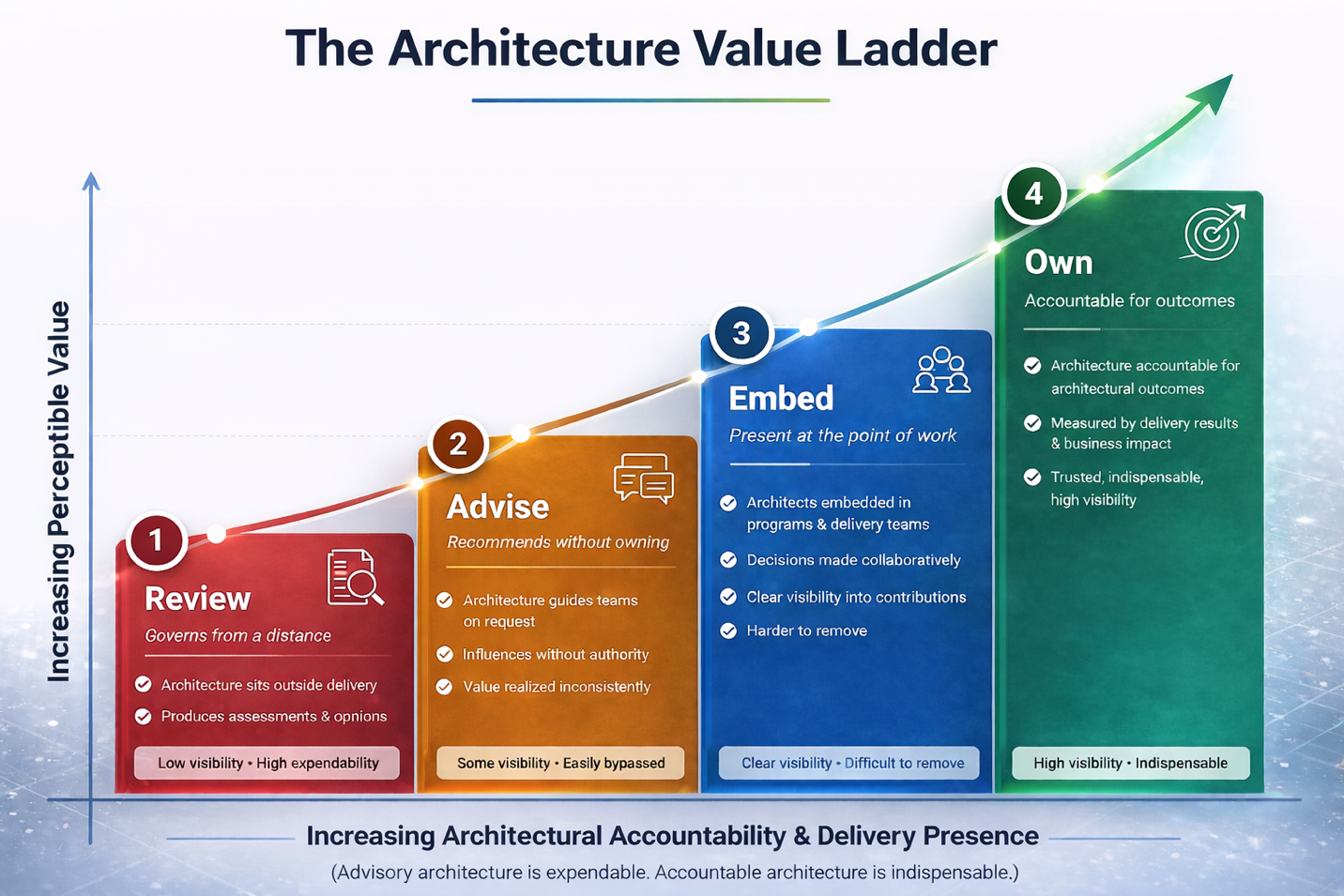
Make Architecture More Valuable: Take Ownership of Enterprise Process Automations and the Service Catalog
Enterprise Architecture becomes more visible and indispensable when it owns operational assets that the enterprise depends on every day. Taking responsibility for enterprise process automations and the service catalog …
read moreBusiness Architecture
Capability Management
Configuration Management
Data & Information Management
AI Exposes the Knowledge Debt Enterprises Can No Longer Ignore
AI is exposing Knowledge Debt: the accumulated loss, fragmentation, and implicit capture of enterprise meaning across systems, data structures, rules, terminology, documentation, and human memory. Making legacy data …
read moreAI Raises the Stakes on Knowing Yourself as an Enterprise
Artificial intelligence sharply increases the cost of carrying incomplete, stale, fragmented, or contradictory enterprise inventory data because AI systems can turn those defects into confident but unreliable answers. …
read more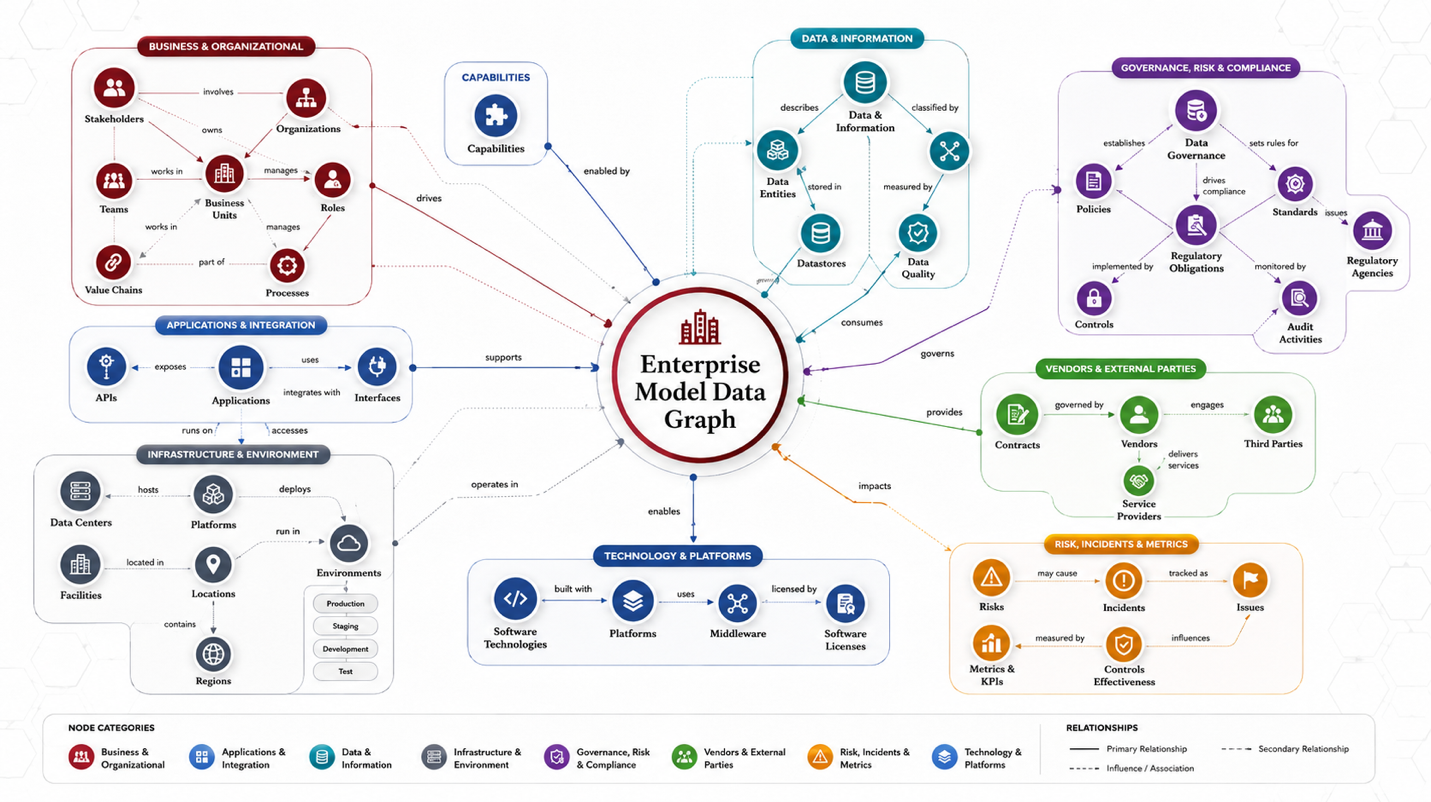
Building and Using Enterprise Knowledge Models with AI-Generated Data Graphs
AI-generated data graphs can transform scattered enterprise knowledge into a connected Enterprise Knowledge Model that humans and AI can query, traverse, visualize, and reason over. Without a governed <u>Taxonomy</u>, …
read more
Enterprise Capabilities Models (ECMs) as a Knowledge Management Tools
Enterprise Capability Models become far more valuable when enterprises use them as shared knowledge structures rather than static architecture diagrams. By relating capabilities to applications, processes, data, risks, …
read more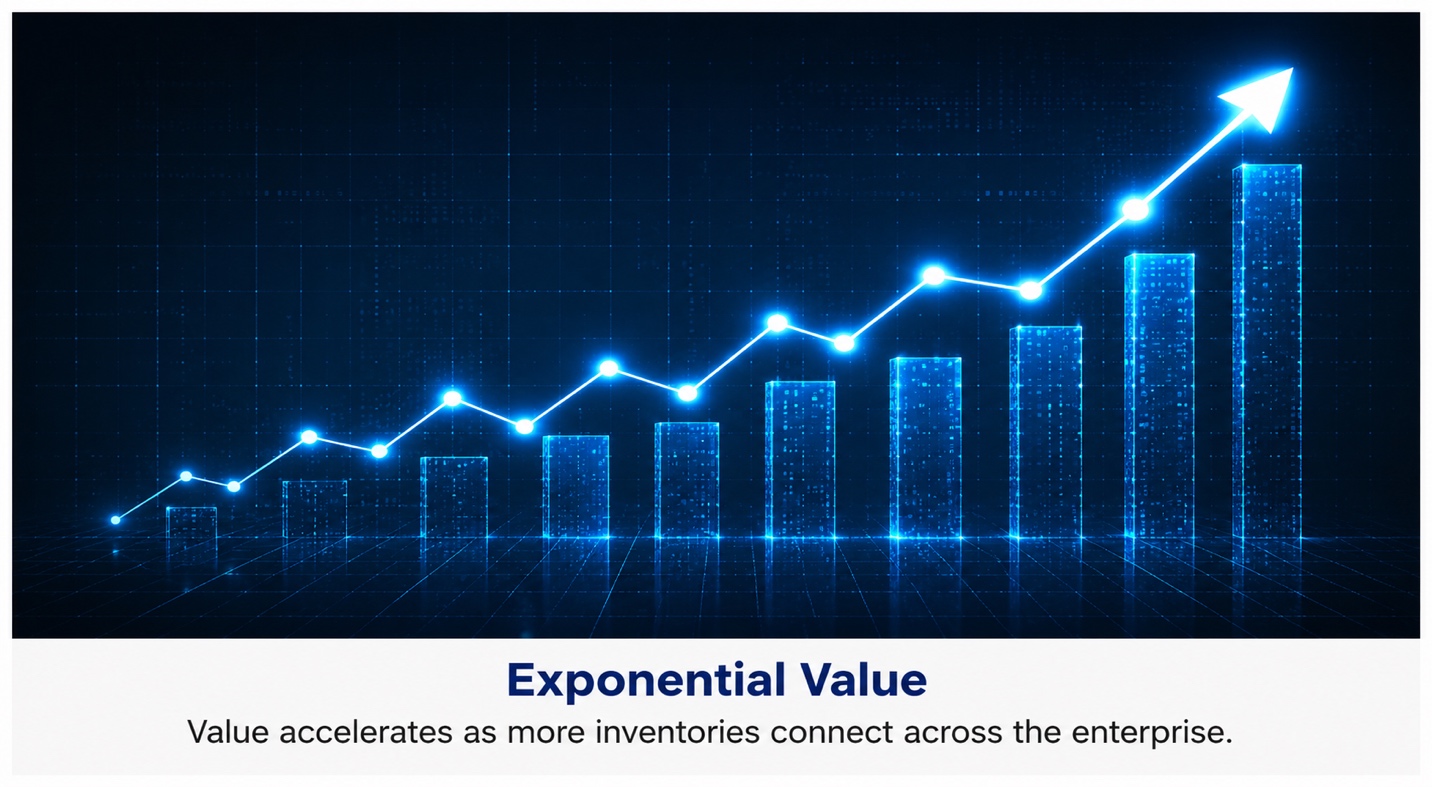
Inventories Are Worth More Together — The Network Effect of a Connected Enterprise Model
Enterprise inventories create their greatest value when they are governed as connected parts of an Enterprise Model rather than as isolated lists. Each new inventory adds its own information and expands the questions …
read moreLegacy Data That Is Machine-Readable Is Not Automatically AI-Ready
Machine-readable legacy data is a starting point, not proof that data is ready for AI consumption. Enterprises that simply connect AI to relational tables, APIs, files, or warehouses may give AI access while still …
read moreMaking Legacy Data AI-Ready Is Knowledge Debt Remediation
Making legacy data semantic and AI-ready is Knowledge Debt remediation: the governed work of making hidden, fragmented, outdated, inconsistent, inaccessible, or poorly governed enterprise meaning explicit. When …
read more
One Source of Truth — How Inventories End the “Whose Numbers Are Right?” Debate
Governed enterprise inventories create a shared and authoritative factual foundation that moves cross-functional debate away from whose data is correct and toward the decisions that matter. Their value depends on …
read more
Stale Data Lies — Why an Inventory Is Never “Done”
An enterprise inventory is only trustworthy while it remains current. Because enterprise assets, owners, relationships, and operating conditions change continuously, inventory maintenance must be treated as an enduring …
read more
The Cost of Not Knowing — Why Enterprise Inventories Are Critical
Enterprises pay a recurring and often hidden cost when they cannot accurately describe their systems, data, ownership, spending, dependencies, and obligations. Governed enterprise inventories reduce this cost by making …
read more
THE IF4IT NOUNZ Data Compiler
IF4IT NOUNZ is a data compiler that applies Data-Driven Compilation and Data-Driven Synthesis to transform governed enterprise data into reusable data graphs, semantic relationships, taxonomies, ontologies, …
read more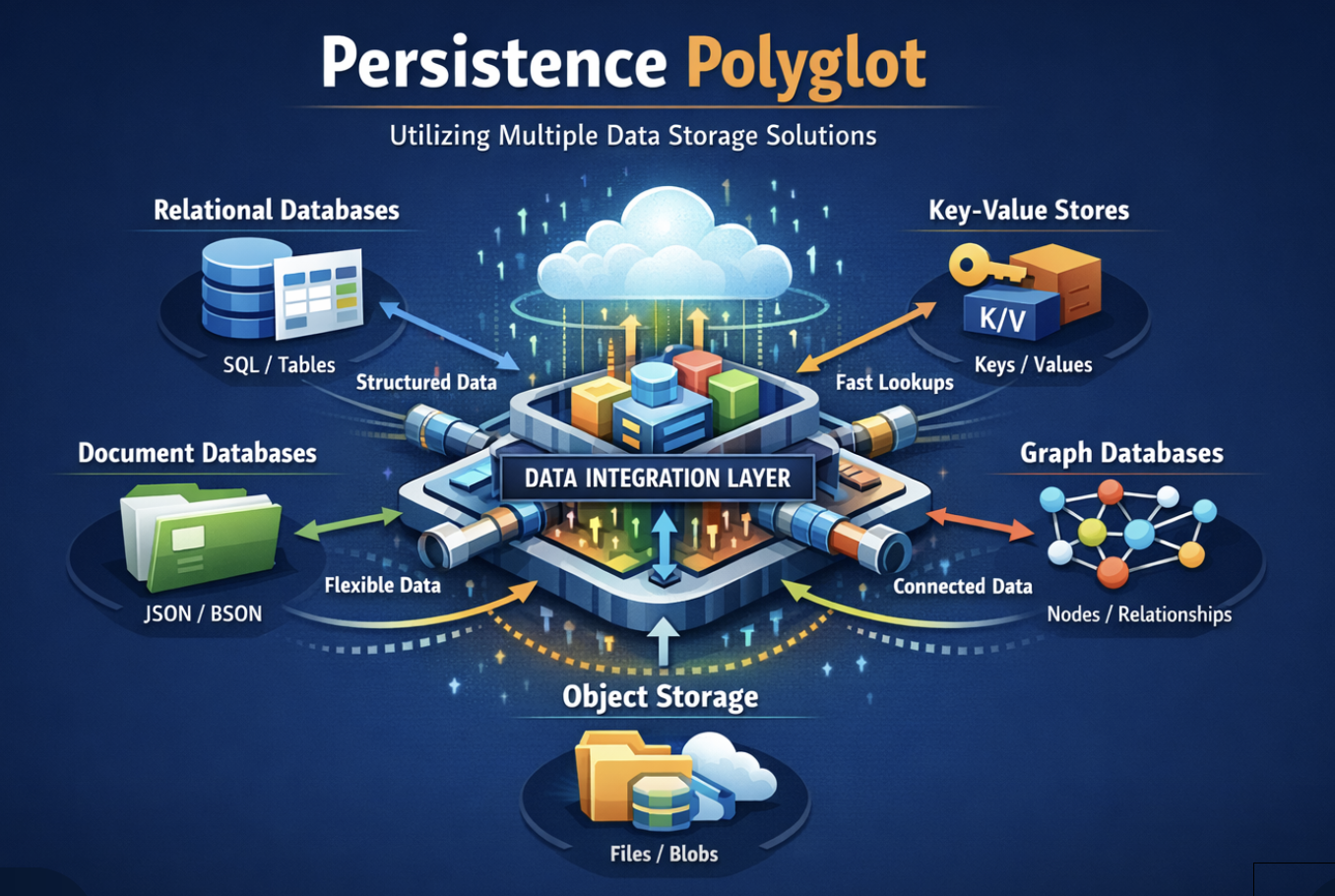
The Persistence Polyglot for Tiny Data and Big Data
Persistence polyglots let applications use multiple storage technologies, each selected for the data structures, access patterns, and scale it handles best. Falling storage costs and managed cloud services make this …
read more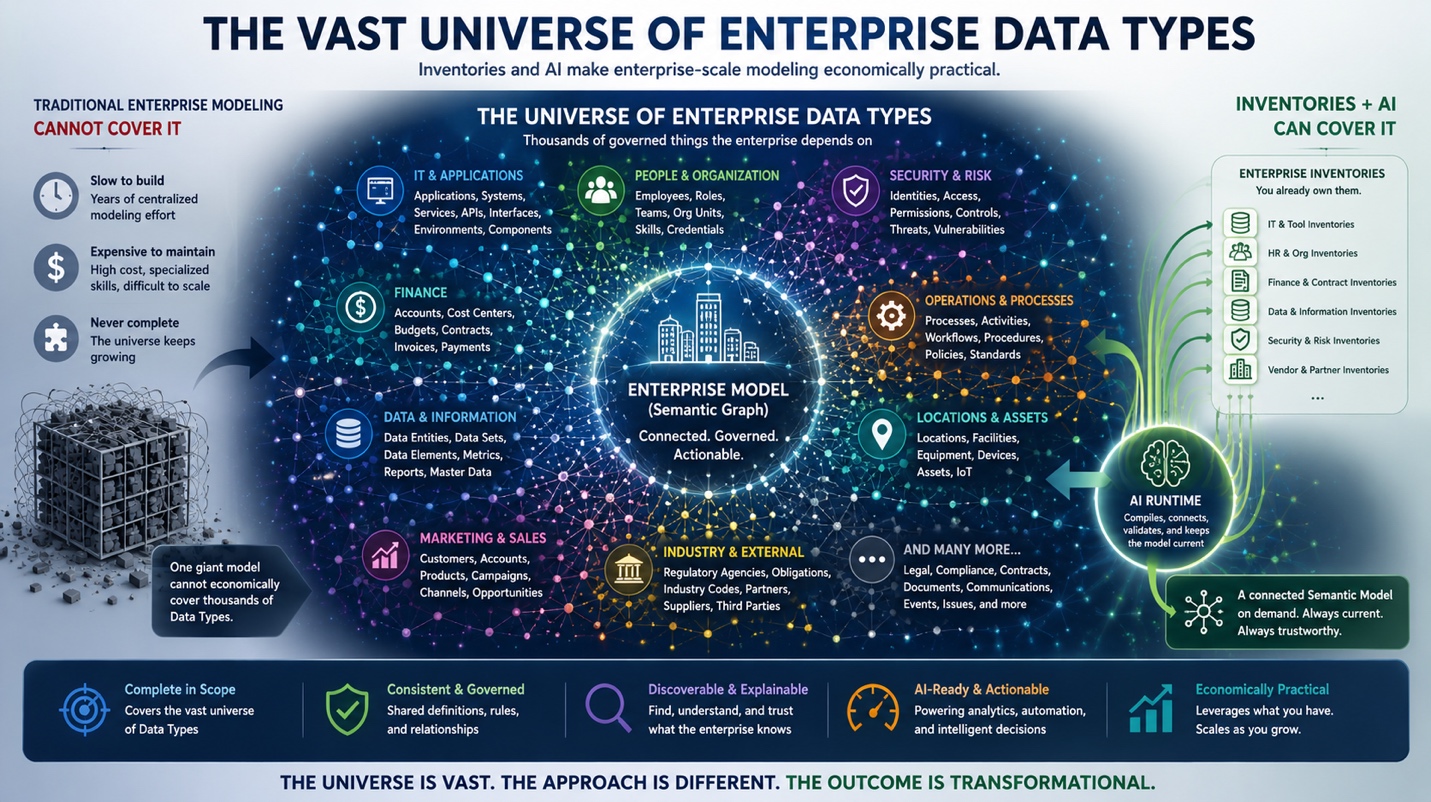
The Universe Of Enterprise Data Types Is Vast — Why Traditional Enterprise Modeling Cannot Cover It But Inventories And AI Can
Traditional centralized enterprise modeling cannot economically or operationally cover the full universe of enterprise Data Types. Enterprises can instead combine governed inventories with AI to compile a connected, …
read more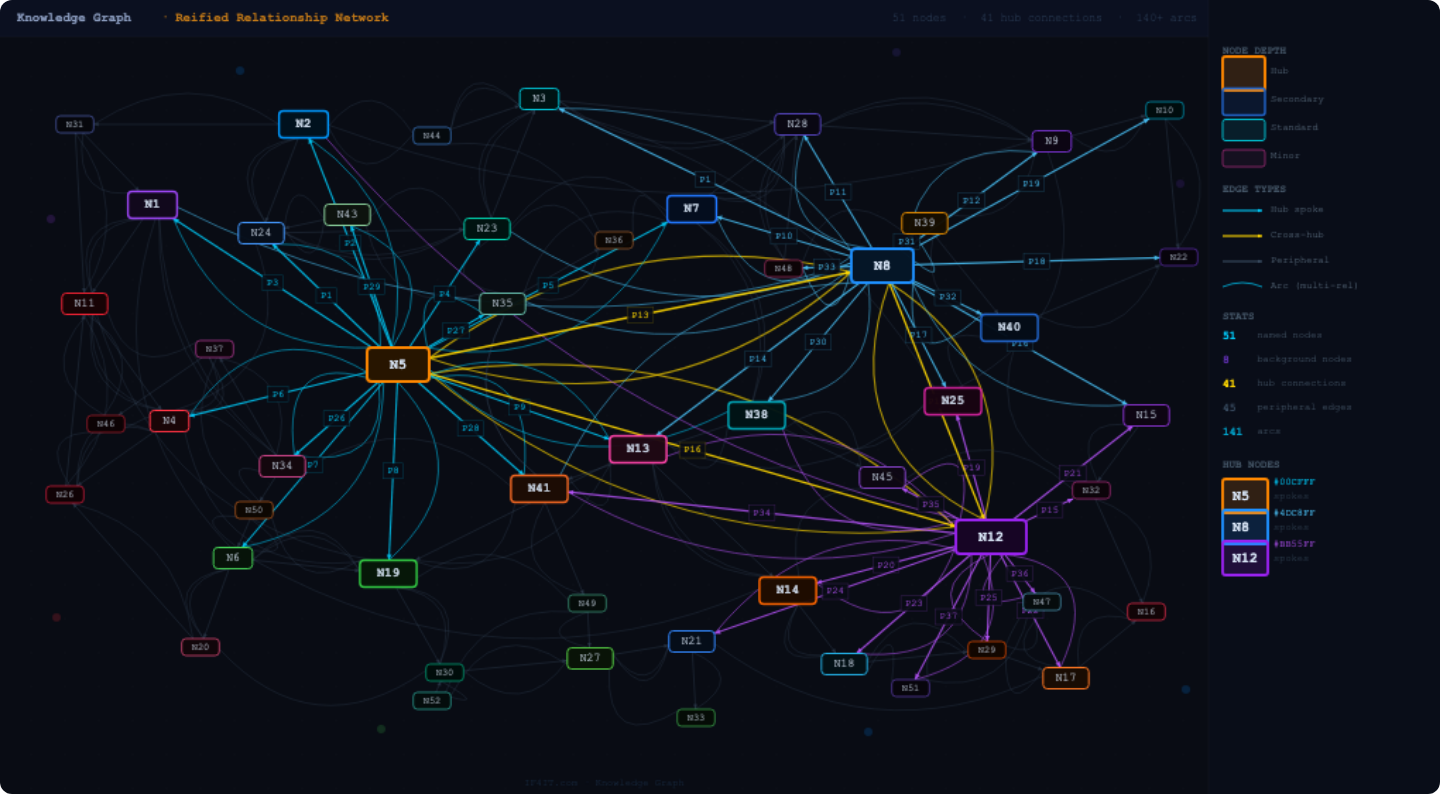
Understanding Reified Relationships, N-Tuples, and How They Give Life to Data
Reification turns a relationship from an implicit connector into a first-class data object that can carry meaning, context, history, and governance. N-tuple depth describes how richly each reified relationship is …
read moreUsing AI to Build and Maintain Enterprise Inventories and Models
Artificial intelligence can dramatically reduce the cost, time, and inconsistency involved in building and maintaining enterprise inventories by extracting, reconciling, cleansing, transforming, populating, and relating …
read more
What You Don’t Know About Your Own Enterprise Is Costing You: Understanding Why Enterprise Inventories Are Critical Knowledge Assets
Enterprise inventories are strategic knowledge assets, not administrative lists. When inventories are complete, current, and connected through governed relationships, they form an Enterprise Model that enables leaders to …
read moreEnterprise Architecture
AI Agents Inventory vs. Registry vs. Catalog: What's the Difference?
An AI Agents Inventory and an AI Agents Registry are the same thing: a governed record of the AI agents an enterprise has, who owns them, what they can do, and what they can reach. An AI Agents Catalog is different: it …
read moreAI Governance Is an Inventory Problem: Why Enterprise AI Governance Starts With an AI Agent Inventory
AI governance is not a new discipline. It is inventory governance applied to a new kind of asset. Enterprises struggling to govern Artificial Intelligence (AI) are usually struggling because they cannot see what AI they …
read moreBuilding and Using Enterprise Knowledge Models with AI-Generated Data Graphs
AI-generated data graphs can transform scattered enterprise knowledge into a connected Enterprise Knowledge Model that humans and AI can query, traverse, visualize, and reason over. Without a governed <u>Taxonomy</u>, …
read moreEnterprise Capabilities Models (ECMs) as a Knowledge Management Tools
Enterprise Capability Models become far more valuable when enterprises use them as shared knowledge structures rather than static architecture diagrams. By relating capabilities to applications, processes, data, risks, …
read more
From Cost Center to Value Engine: Reframing the Role of IT in the Modern Enterprise
IT becomes a value engine when its operating model, investment decisions, and performance measures are explicitly tied to measurable business outcomes. Reframing IT requires product and service ownership, financial …
read moreInventories Are Worth More Together — The Network Effect of a Connected Enterprise Model
Enterprise inventories create their greatest value when they are governed as connected parts of an Enterprise Model rather than as isolated lists. Each new inventory adds its own information and expands the questions …
read more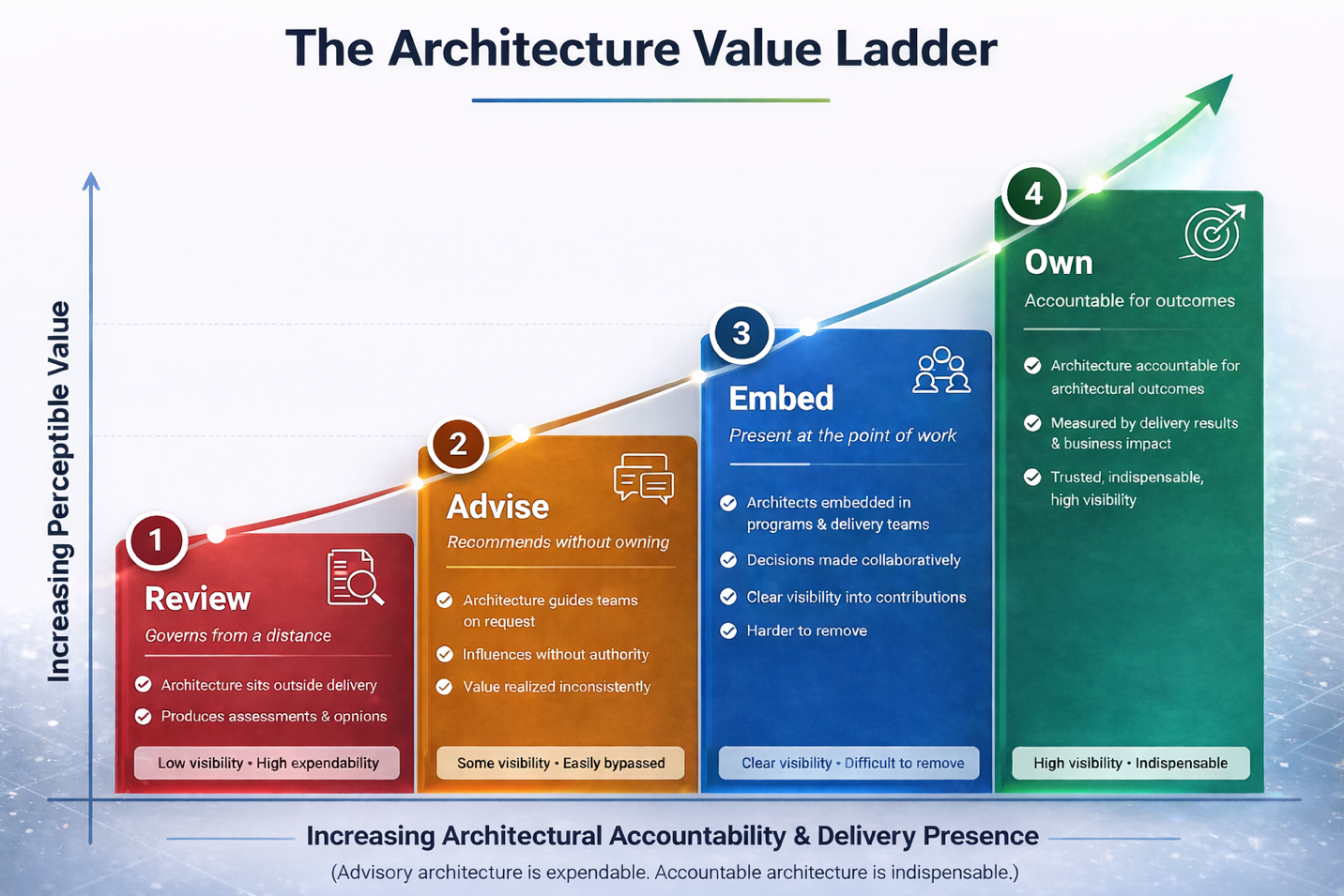
Make Architecture More Valuable: Have Enterprise Architecture Own the CMDB
Enterprise Architecture should own and govern the Configuration Management Database because Architecture has the upstream lifecycle visibility, cross-domain scope, and modeling discipline required to maintain its logical …
read more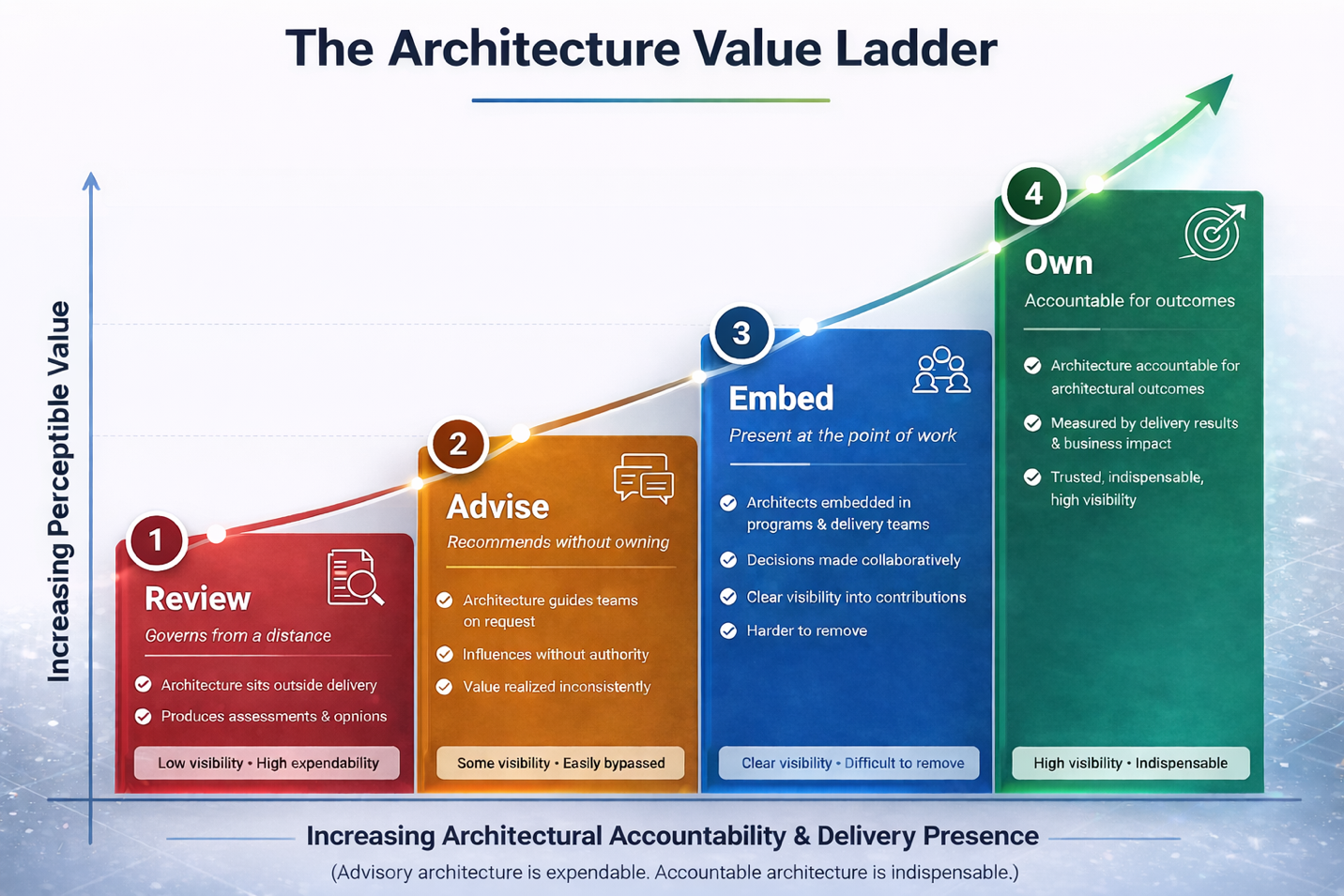
Make Architecture More Valuable: Take on At-Risk & High-Risk Initiatives
Architecture becomes indispensable when it moves beyond advisory governance and accepts accountability for the enterprise’s most consequential delivery outcomes. A dedicated At-Risk Architecture Practice embeds senior, …
read moreMake Architecture More Valuable: Take Ownership of Enterprise Process Automations and the Service Catalog
Enterprise Architecture becomes more visible and indispensable when it owns operational assets that the enterprise depends on every day. Taking responsibility for enterprise process automations and the service catalog …
read more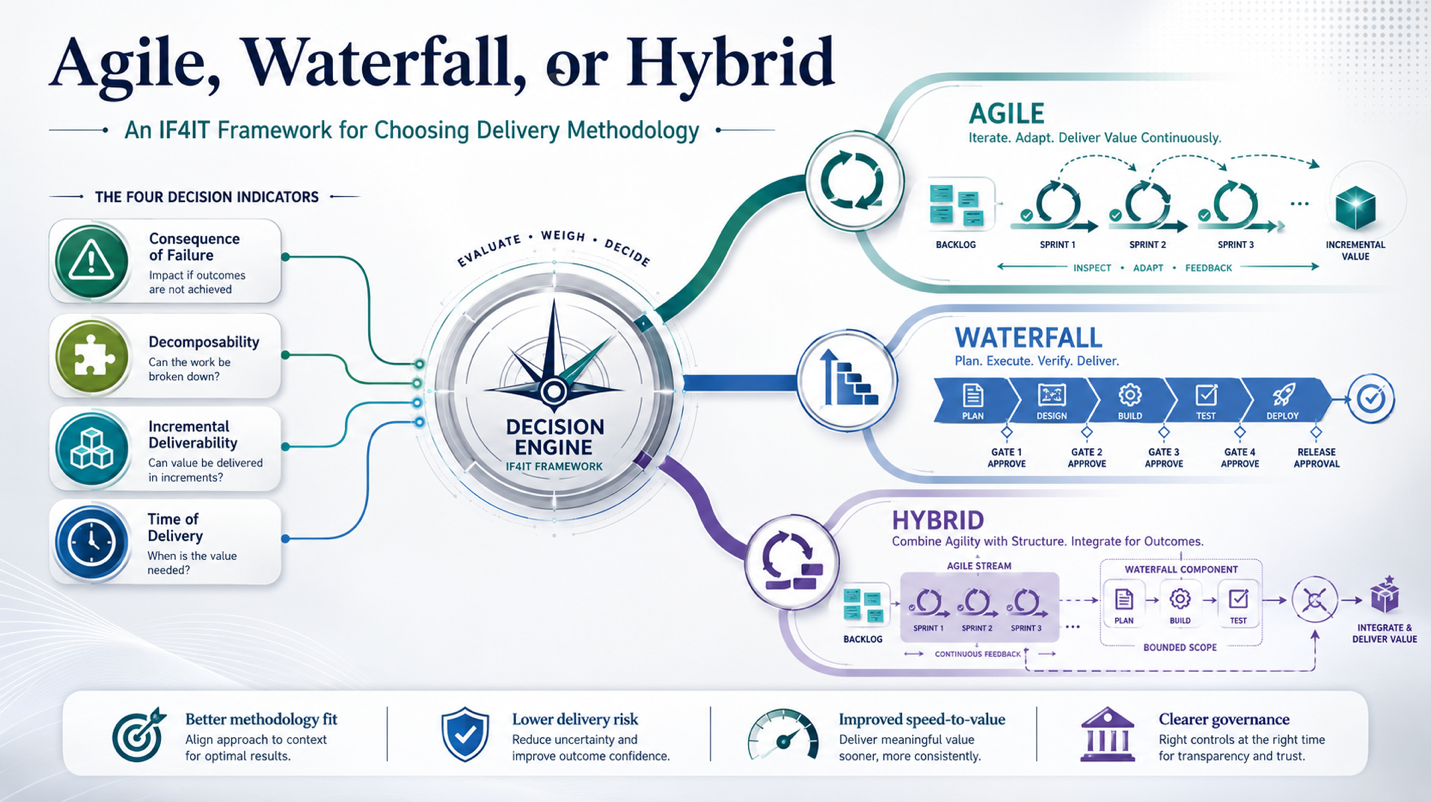
Not Everything Can Be Agile
Delivery methodology must be selected according to the intrinsic characteristics and risks of the work, not imposed as an enterprise-wide preference. Agile is appropriate when work can be decomposed into independently …
read moreShadow AI Agents: Why You Can't Govern the Agents You Can't See
Shadow AI agents are AI agents running inside an enterprise that no one has recorded, owns, or governs. They are not a new category of problem; they are the AI form of an old one, the ungoverned asset, and they arise for …
read moreThe Universe Of Enterprise Data Types Is Vast — Why Traditional Enterprise Modeling Cannot Cover It But Inventories And AI Can
Traditional centralized enterprise modeling cannot economically or operationally cover the full universe of enterprise Data Types. Enterprises can instead combine governed inventories with AI to compile a connected, …
read moreUnderstanding Reified Relationships, N-Tuples, and How They Give Life to Data
Reification turns a relationship from an implicit connector into a first-class data object that can carry meaning, context, history, and governance. N-tuple depth describes how richly each reified relationship is …
read moreUsing AI to Build and Maintain Enterprise Inventories and Models
Artificial intelligence can dramatically reduce the cost, time, and inconsistency involved in building and maintaining enterprise inventories by extracting, reconciling, cleansing, transforming, populating, and relating …
read more
Why Business Architecture and Enterprise Architecture Practices Often Fail
Architecture practices earn durable executive support when they are accountable for measurable business outcomes rather than documents, diagrams, and advisory activity alone. When Business Architecture and Enterprise …
read moreInformation Technology Management
From Cost Center to Value Engine: Reframing the Role of IT in the Modern Enterprise
IT becomes a value engine when its operating model, investment decisions, and performance measures are explicitly tied to measurable business outcomes. Reframing IT requires product and service ownership, financial …
read moreUnderstanding Reified Relationships, N-Tuples, and How They Give Life to Data
Reification turns a relationship from an implicit connector into a first-class data object that can carry meaning, context, history, and governance. N-tuple depth describes how richly each reified relationship is …
read moreWelcome to the IF4IT
IF4IT provides openly available guidance that helps IT leaders and practitioners design, build, operate, and continuously improve high-functioning technology organizations faster and more affordably. Its materials …
read moreInventory Management
Inventories Are Worth More Together — The Network Effect of a Connected Enterprise Model
Enterprise inventories create their greatest value when they are governed as connected parts of an Enterprise Model rather than as isolated lists. Each new inventory adds its own information and expands the questions …
read moreOne Source of Truth — How Inventories End the “Whose Numbers Are Right?” Debate
Governed enterprise inventories create a shared and authoritative factual foundation that moves cross-functional debate away from whose data is correct and toward the decisions that matter. Their value depends on …
read moreStale Data Lies — Why an Inventory Is Never “Done”
An enterprise inventory is only trustworthy while it remains current. Because enterprise assets, owners, relationships, and operating conditions change continuously, inventory maintenance must be treated as an enduring …
read moreThe Cost of Not Knowing — Why Enterprise Inventories Are Critical
Enterprises pay a recurring and often hidden cost when they cannot accurately describe their systems, data, ownership, spending, dependencies, and obligations. Governed enterprise inventories reduce this cost by making …
read moreUsing AI to Build and Maintain Enterprise Inventories and Models
Artificial intelligence can dramatically reduce the cost, time, and inconsistency involved in building and maintaining enterprise inventories by extracting, reconciling, cleansing, transforming, populating, and relating …
read moreWhat You Don’t Know About Your Own Enterprise Is Costing You: Understanding Why Enterprise Inventories Are Critical Knowledge Assets
Enterprise inventories are strategic knowledge assets, not administrative lists. When inventories are complete, current, and connected through governed relationships, they form an Enterprise Model that enables leaders to …
read moreYour Enterprise AI Is Only as Good as Your Enterprise Inventories
Domain-specific AI can succeed with clean, bounded data, but enterprise-spanning AI depends on governed, current, and connected enterprise inventories. Better models, prompts, or retrieval techniques cannot compensate …
read moreIT Governance
AI Agents Inventory vs. Registry vs. Catalog: What's the Difference?
An AI Agents Inventory and an AI Agents Registry are the same thing: a governed record of the AI agents an enterprise has, who owns them, what they can do, and what they can reach. An AI Agents Catalog is different: it …
read moreAI Governance Is an Inventory Problem: Why Enterprise AI Governance Starts With an AI Agent Inventory
AI governance is not a new discipline. It is inventory governance applied to a new kind of asset. Enterprises struggling to govern Artificial Intelligence (AI) are usually struggling because they cannot see what AI they …
read moreShadow AI Agents: Why You Can't Govern the Agents You Can't See
Shadow AI agents are AI agents running inside an enterprise that no one has recorded, owns, or governs. They are not a new category of problem; they are the AI form of an old one, the ungoverned asset, and they arise for …
read moreKnowledge Management
AI Exposes the Knowledge Debt Enterprises Can No Longer Ignore
AI is exposing Knowledge Debt: the accumulated loss, fragmentation, and implicit capture of enterprise meaning across systems, data structures, rules, terminology, documentation, and human memory. Making legacy data …
read moreAI Raises the Stakes on Knowing Yourself as an Enterprise
Artificial intelligence sharply increases the cost of carrying incomplete, stale, fragmented, or contradictory enterprise inventory data because AI systems can turn those defects into confident but unreliable answers. …
read moreAI Right Isn’t About the Model You Buy — It’s About What You Give It to Reason Over
Enterprise-wide Artificial Intelligence cannot become trustworthy merely by selecting a more capable model. It requires a governed, connected substrate that represents the enterprise across domains. Vertical AI can …
read moreBuilding and Using Enterprise Knowledge Models with AI-Generated Data Graphs
AI-generated data graphs can transform scattered enterprise knowledge into a connected Enterprise Knowledge Model that humans and AI can query, traverse, visualize, and reason over. Without a governed <u>Taxonomy</u>, …
read moreEnterprise Capabilities Models (ECMs) as a Knowledge Management Tools
Enterprise Capability Models become far more valuable when enterprises use them as shared knowledge structures rather than static architecture diagrams. By relating capabilities to applications, processes, data, risks, …
read moreInventories Are Worth More Together — The Network Effect of a Connected Enterprise Model
Enterprise inventories create their greatest value when they are governed as connected parts of an Enterprise Model rather than as isolated lists. Each new inventory adds its own information and expands the questions …
read moreMaking Legacy Data AI-Ready Is Knowledge Debt Remediation
Making legacy data semantic and AI-ready is Knowledge Debt remediation: the governed work of making hidden, fragmented, outdated, inconsistent, inaccessible, or poorly governed enterprise meaning explicit. When …
read moreOne Source of Truth — How Inventories End the “Whose Numbers Are Right?” Debate
Governed enterprise inventories create a shared and authoritative factual foundation that moves cross-functional debate away from whose data is correct and toward the decisions that matter. Their value depends on …
read moreStale Data Lies — Why an Inventory Is Never “Done”
An enterprise inventory is only trustworthy while it remains current. Because enterprise assets, owners, relationships, and operating conditions change continuously, inventory maintenance must be treated as an enduring …
read moreThe Cost of Not Knowing — Why Enterprise Inventories Are Critical
Enterprises pay a recurring and often hidden cost when they cannot accurately describe their systems, data, ownership, spending, dependencies, and obligations. Governed enterprise inventories reduce this cost by making …
read moreTHE IF4IT NOUNZ Data Compiler
IF4IT NOUNZ is a data compiler that applies Data-Driven Compilation and Data-Driven Synthesis to transform governed enterprise data into reusable data graphs, semantic relationships, taxonomies, ontologies, …
read moreThe Universe Of Enterprise Data Types Is Vast — Why Traditional Enterprise Modeling Cannot Cover It But Inventories And AI Can
Traditional centralized enterprise modeling cannot economically or operationally cover the full universe of enterprise Data Types. Enterprises can instead combine governed inventories with AI to compile a connected, …
read moreUnderstanding Reified Relationships, N-Tuples, and How They Give Life to Data
Reification turns a relationship from an implicit connector into a first-class data object that can carry meaning, context, history, and governance. N-tuple depth describes how richly each reified relationship is …
read moreUsing AI to Build and Maintain Enterprise Inventories and Models
Artificial intelligence can dramatically reduce the cost, time, and inconsistency involved in building and maintaining enterprise inventories by extracting, reconciling, cleansing, transforming, populating, and relating …
read moreWhat You Don’t Know About Your Own Enterprise Is Costing You: Understanding Why Enterprise Inventories Are Critical Knowledge Assets
Enterprise inventories are strategic knowledge assets, not administrative lists. When inventories are complete, current, and connected through governed relationships, they form an Enterprise Model that enables leaders to …
read moreYour Enterprise AI Is Only as Good as Your Enterprise Inventories
Domain-specific AI can succeed with clean, bounded data, but enterprise-spanning AI depends on governed, current, and connected enterprise inventories. Better models, prompts, or retrieval techniques cannot compensate …
read moreProcess Management
Product Management
Project Management
Make Architecture More Valuable: Take on At-Risk & High-Risk Initiatives
Architecture becomes indispensable when it moves beyond advisory governance and accepts accountability for the enterprise’s most consequential delivery outcomes. A dedicated At-Risk Architecture Practice embeds senior, …
read moreNot Everything Can Be Agile
Delivery methodology must be selected according to the intrinsic characteristics and risks of the work, not imposed as an enterprise-wide preference. Agile is appropriate when work can be decomposed into independently …
read more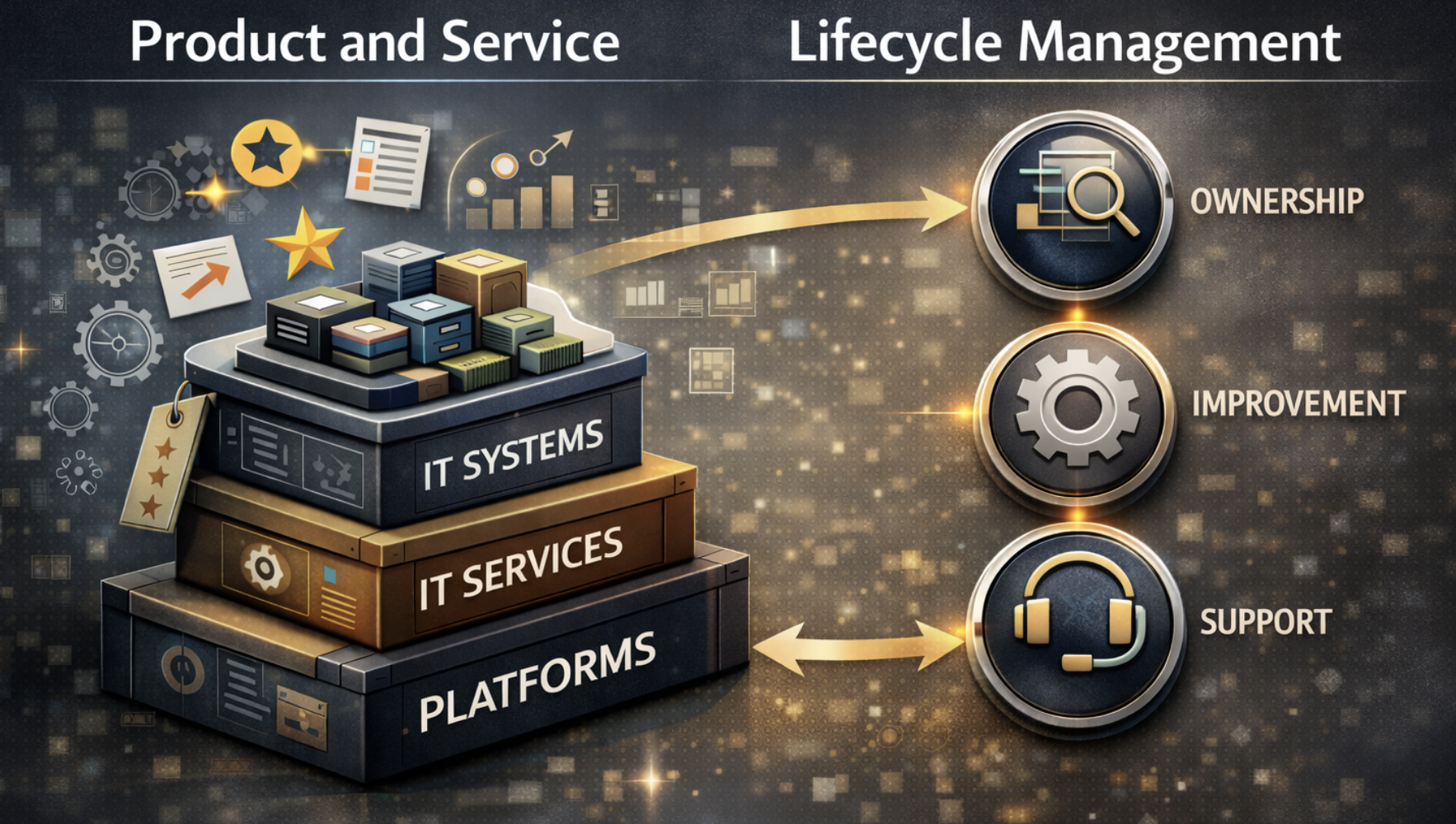
Product Thinking in IT: Treating IT Systems, Platforms, and Services Like Products
Internal IT systems, platforms, and services create more durable value when they are managed as long-lived products rather than temporary projects. Persistent ownership, lifecycle management, continuous improvement, and …
read moreRequirements Management
Service Management
Building Service Catalogs That Actually Work
A service catalog succeeds when business stakeholders can quickly understand what IT can do for them, submit requests through a clear and reliable process, and receive outcomes that match published expectations. …
read moreMake Architecture More Valuable: Take Ownership of Enterprise Process Automations and the Service Catalog
Enterprise Architecture becomes more visible and indispensable when it owns operational assets that the enterprise depends on every day. Taking responsibility for enterprise process automations and the service catalog …
read moreSoftware Engineering
Browse all IF4IT content on the Catalog.