Your Enterprise AI Is Only as Good as Your Enterprise Inventories
International Foundation for Information Technology (IF4IT)
Abstract
Something strange is happening in the enterprise AI conversation. Domain after domain reports successful AI deployments — fraud detection, document classification, demand forecasting, contact-center automation, code completion. The successes are real. And yet when enterprises try to extend AI from those bounded successes to questions that span the whole business, the results disappoint. The same models that work brilliantly in their lanes fail at enterprise scope. The puzzle is real, and the answer is in a distinction most enterprises haven’t yet made: the AI that succeeds inside a domain and the AI that reasons across the enterprise are not the same kind of system, and they do not have the same relationship to inventory data. The first kind needs clean data inside its domain. The second kind needs governed inventories beneath everything it touches. This article makes the distinction concrete, explains why it changes how enterprises should think about AI investment, and points the reader to the IF4IT Enterprise Inventory Management Best Practices document for the foundation that makes trustworthy enterprise AI possible as part of a broader Enterprise Model.
Author: The International Foundation for Information Technology (IF4IT)
The Puzzle
Something strange is happening in the enterprise AI conversation.
Domain after domain reports successful AI deployments. Fraud detection models that catch what rules-based systems miss. Document classifiers that route incoming work faster than humans. Demand-forecasting systems that have measurably improved planning accuracy. Contact-center AI that handles routine cases at scale. Code-completion tools that have changed how developers write software. None of these successes is hype. They are real, they are measurable, and they are accelerating.
And yet, when enterprises try to extend AI from those bounded successes to questions that span the whole business — which of our applications are exposed to this new regulation? If this vendor fails, what breaks? Where is our risk concentrated across the company? — the results disappoint. Pilots that demoed beautifully produce confident, fluent, and wrong answers when asked anything that crosses business domains. Trust erodes. Adoption stalls. The investment doesn’t pay back, and nobody is quite sure why.
The puzzle is real, and it is worth taking seriously, because the answer to it has direct implications for where enterprises put their AI dollars and what they expect to get back. The answer is a distinction most enterprises haven’t yet made — a distinction obscured by the fact that all of these systems are called “enter prise AI” when they are, in important ways, two different kinds of system entirely.
Not All Enterprise AI Is the Same
These three pairings are facets of the same distinction, not three different distinctions — different ways of seeing the same line so that whichever framing matches a reader’s mental model, the line itself is visible.
Domain-specific AI vs. enterprise AI. This is the framing that captures the scope of the AI’s job. Domain-specific AI does one job inside one business domain — detect fraud, classify documents, forecast demand, complete code. Its job is bounded, its inputs are bounded, its outputs are bounded. The “enter prise” in its name is incidental: it happens to be deployed inside an enterprise, but its work is not about the enterprise. Enterprise AI, in the meaningful sense, is different. Its job is to reason about the enterprise itself — to answer questions about what the business is, what it has, what it depends on, where it’s exposed. The enterprise is not the setting; the enterprise is the subject.
Narrow AI vs. broad AI. This is the framing that captures the breadth of the AI’s data substrate. Narrow AI operates over a curated, bounded dataset chosen specifically for its task. The fraud model sees transactions. The classifier sees documents. The forecaster sees historical demand. The data is narrow because the question is narrow, and a small, well-shaped substrate is sufficient. Broad AI is different. To reason across the enterprise, it must reason over data that spans the enterprise — many different kinds of things, owned by different functions, governed (or not) by different standards. The substrate cannot be narrow because the questions are not narrow.
Bounded AI vs. enterprise-spanning AI. This is the framing that captures the shape of the questions the AI must answer. Bounded AI answers questions that fit inside one domain: is this transaction fraud? what category does this document belong to? The boundaries of the question and the boundaries of the data align. Enterprise-spanning AI answers questions that cross boundaries: what applications process regulated data? which business capabilities are at risk if this vendor fails? The question reaches across the enterprise, and the data substrate must reach with it.
Three framings, one line. On one side: AI that does a specific job inside a specific domain on specific data. On the other side: AI whose job is to reason about the enterprise as a whole, whose questions cross domains, and whose data substrate must therefore span the entire business. The line matters because the two sides have fundamentally different relationships to the data beneath them — and the failure to distinguish them is, more than any other single factor, why so much enterprise AI investment is producing confident, fluent, and wrong answers.
Why Domain-Specific AI Doesn’t Need Governed Inventories
It’s worth saying clearly: domain-specific AI is often genuinely excellent, and it does not require governed enterprise inventories to be so. Pretending otherwise would be both inaccurate and a disservice to the real successes the field has produced.
The reason domain-specific AI can succeed without governed inventories is that its data dependency is narrow and self-contained. A fraud-detection model needs transaction data, account data, and historical fraud labels. That data has owners, has quality controls, has a defined schema, and lives in systems specifically designed to hold it. The model’s job — distinguishing fraudulent transactions from legitimate ones — does not require reasoning about applications, vendors, capabilities, or regulatory obligations. It requires reasoning about transactions. As long as the transaction data is clean and complete and the model has learned the right patterns, the system works. Governed enterprise inventories would not make it work better; they are not in its operating loop.
The same is true across the bounded successes that dominate the current AI conversation. A document classifier needs labeled documents. A demand forecaster needs sales history and seasonality signals. A contact-center model needs conversation transcripts and outcome data. A code-completion model needs code. In each case the data the system needs is the data it consumes directly, narrowly scoped, and the model’s success depends on the quality of that narrow data — not on the enterprise’s broader self-knowledge.
This is also why domain-specific AI is evaluable. The narrow scope means there are answers in the world that can be checked. Did we catch the fraud or didn’t we? Did the forecast match what actually happened? Did the classifier route correctly? The model’s outputs can be measured against reality, and the model can be improved on the basis of that measurement. The combination of narrow data and narrow evaluation is what makes domain-specific AI a tractable engineering problem, and it is the reason the wave of bounded AI successes is genuine.
Crediting this honestly matters because the next argument is sharper for it. The pattern that works for domain-specific AI — clean data inside a bounded domain — does not generalize to enterprise AI. The very thing that makes domain-specific AI tractable is what enterprise AI doesn’t have: a narrow, bounded, curated data substrate against which the model can be trained and evaluated. The bounded successes are not a template for the unbounded job. They are the reason the unbounded job looks like it should be tractable when it isn’t.
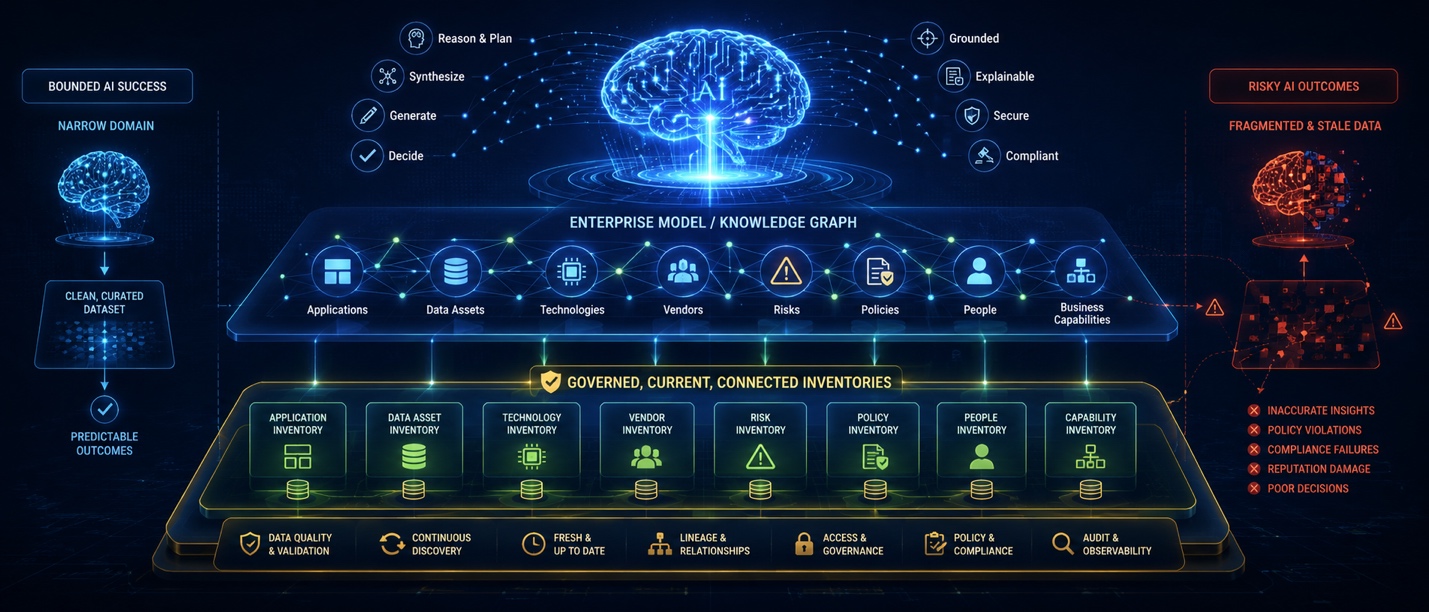
Why Enterprise AI Does Need Governed Inventories
Enterprise AI is a different kind of system because the questions it is asked to answer are categorically different.
Consider what it actually means to ask an AI a question like “which of our applications process regulated customer data and run on technologies approaching end of life?” That single question reaches into at least four governed inventories: applications, data and information (with regulatory sensitivity classifications), technologies (with lifecycle status), and the relationships among them. There is no single data source that can answer it. There is no narrow, bounded substrate that contains the answer. The answer exists, if it exists at all, in the connections among governed inventories — which is to say, in a connected Enterprise Model. If those inventories don’t exist, the question has no answer. If they exist but aren’t governed — if their accuracy can’t be trusted, their currency isn’t maintained, their connections aren’t defined — then the AI will not refuse to answer. It will answer anyway. Confidently. Fluently. And wrongly.
This is the failure pattern enterprises are quietly experiencing. The AI is given access to whatever inventory-shaped data exists — sometimes complete, sometimes partial, sometimes stale by years, sometimes contradicting other sources the AI also has access to — and it produces an answer. The answer reads plausibly. The bullets are well-formed. The reasoning sounds sound. There is no mechanism inside the AI to know that the underlying applications inventory is missing twelve systems, that the data sensitivity flags were never populated for a third of the rows, or that the EOL dates reflect a stale 2024 snapshot. The AI cannot see the gaps in its substrate. It can only see what it is given, and it will reason from what it is given to a confident conclusion every time.
The phrase that captures this most precisely is confident, fluent, and wrong. Each of the three matters. Confident, because the AI presents its answer with no signal of uncertainty about the data beneath it. Fluent, because the answer is in clean, well-structured prose that reads as if it knows what it’s talking about. Wrong, because the underlying substrate does not support the conclusion. This combination is more dangerous than any of the three alone. A confident-but-disfluent answer can be discounted. A fluent-but-tentative answer prompts verification. A confident, fluent, wrong answer slides into the enterprise’s decision-making and compounds whatever decisions are made on top of it. The cost is not the AI’s; it is the enterprise’s, paid in decisions made on bad data the AI presented as good.
The only sustainable fix is structural, not algorithmic. No prompt-engineering technique, no fine-tuning, no model upgrade, no retrieval-augmentation strategy will solve a substrate problem. If the inventories beneath the AI are missing, fragmented, stale, or ungoverned, the AI’s output will reflect those defects no matter how sophisticated the model. The work that makes enterprise AI trustworthy is not, in the end, work on the AI. It is work on the inventories beneath it.
What “Trustworthy” Actually Costs
To say that enterprise AI needs governed inventories is to say something concrete, and the concrete thing is worth being honest about. Governing inventories is not free, and the investment cannot be redirected toward AI — they are not substitutes. The investment is the precondition for the AI to be worth anything.
Governing an inventory means assigning clear ownership to it, defining the attributes it tracks, populating it from authoritative sources, connecting it to the other inventories it relates to, maintaining its currency on a defined cadence, and treating its accuracy as a measured quality the organization commits to over time. Doing this for one inventory is real work. Doing it for the connected set of inventories that an enterprise AI needs to reason across is meaningful work — measured in months and years, not weeks, and requiring sustained organizational attention rather than a one-time push.
The honest framing for enterprise leaders is this: an enterprise that wants trustworthy AI answers about itself is committing to know itself rigorously. The AI cannot do that work in advance; it can only consume the knowledge the enterprise has chosen to encode. The enterprises that get the most out of enterprise AI are not the ones with the largest AI budgets. They are the ones that have done — or are willing to do — the inventory work that makes the AI’s answers worth listening to. Where that work hasn’t been done, no amount of AI investment compensates.
This reframes how the AI investment thesis should look. Buying better models, more sophisticated agents, or larger context windows does not address the substrate problem; it just produces more confident, more fluent versions of the same wrong answers. The high-leverage investment for enterprise AI is one layer below the AI itself — in the inventories the AI must reason over. Enterprises that recognize this redirect their attention; enterprises that don’t keep buying capabilities they cannot use.
Where to Go Next
The full treatment of how to build and govern the inventories that make trustworthy enterprise AI possible — including how to define them, populate them, connect them into a coherent Enterprise Model, maintain them as the reality they describe changes, and recognize when their absence is the actual cause of an AI failure that looks like a model problem — is in the IF4IT Enterprise Inventory Management Best Practices document. The document devotes a specific section, “Treat enterprise inventories as the foundation for trustworthy enterprise AI”, to the argument this article distills. Enterprise inventories are a critical foundation for designing and establishing your broader Enterprise Model, which is the foundation for establishing trustworthy AI reasoning.
Domain-specific AI succeeds when its data is clean. Enterprise AI succeeds when the enterprise knows itself. The two are not the same problem, and treating them as the same is why so much of today’s enterprise AI investment will not pay back.
Published by IF4IT.com — The International Foundation for Information Technology
Back to Articles PageHow to cite this page
When referencing this page in academic work, internal standards, or external publications, include the page title, IF4IT as publisher, the URL, and your access date.
Example (informal web citation):
International Foundation for Information Technology (IF4IT). Your Enterprise AI Is Only as Good as Your Enterprise Inventories. https://if4it.org/articles/2026-05-29-your-enterprise-ai-is-only-as-good-as-your-enterprise-inventories/ (accessed 2026-06-23).
See About Us for content governance and site-wide citation guidance.