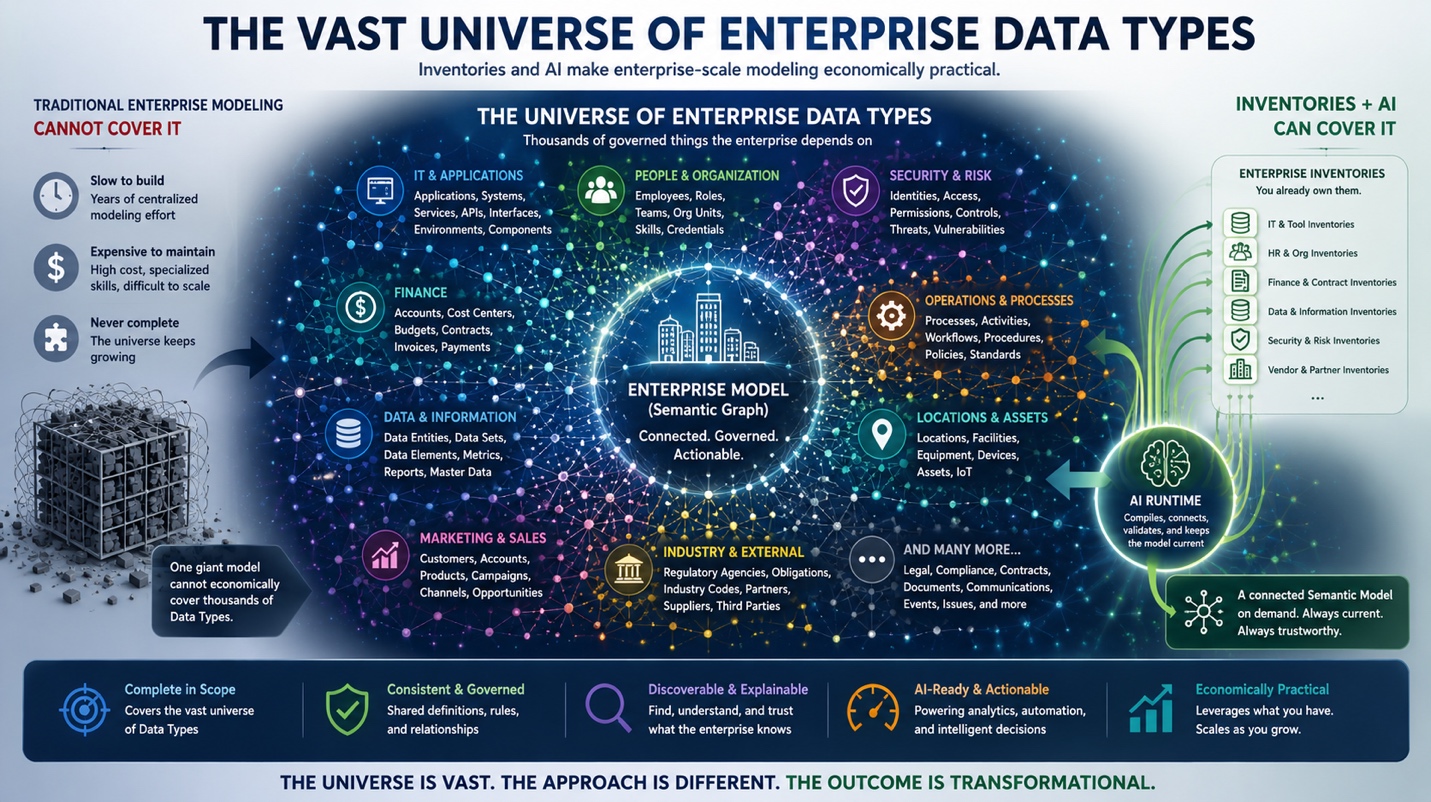
The Universe Of Enterprise Data Types Is Vast — Why Traditional Enterprise Modeling Cannot Cover It But Inventories And AI Can
International Foundation for Information Technology (IF4IT)
Abstract
The universe of Data Types an enterprise needs to govern is vast — genuinely in the low thousands when an enterprise of meaningful complexity is decomposed honestly, with the specific count varying substantially by industry, by operational complexity, and by the depth of specialization an enterprise chooses to govern. This vastness is the underlying reason traditional Enterprise Modeling has remained a second-class citizen in most enterprises: the time, cost, and complexity of building and maintaining a single integrated model that covers the full universe of Data Types are simply too high to justify against the revenue-generating priorities that Business domain systems (CRM, ERP, Product Management, Customer Support, and others) bring to the funding conversation. This article walks the reader through the vastness of the universe, makes the economic and architectural case for why the traditional approach cannot cover it, and then introduces a different approach: coupling the inventories an enterprise already owns with AI as the runtime that compiles them into a connected Semantic Model on demand. The full apparatus of that approach is developed in the IF4IT Enterprise Model and Modeling Best Practices document; this article makes the case for why that document is worth reading.
Why the Enterprise Model Has Always Been a Second-Class Citizen
In most enterprises, the Enterprise Model is a second-class citizen. The investments that get funded, staffed, and prioritized are the investments tied directly to revenue — the Customer Relationship Management (CRM) and customer support platforms that capture and retain customers, the Enterprise Resource Planning (ERP) systems that run the financial and operational core, the Product Management and engineering systems that build what the enterprise sells, the marketing and sales analytics platforms that drive growth. These systems are funded because the business consequences of not funding them are immediate and visible. If the CRM goes down, sales calls stop. If the ERP breaks, invoices do not go out. If Product Management loses its backlog, releases slip. The investment case writes itself.
The Enterprise Model occupies a different position. Its value is real but diffuse, accruing across many decisions, many domains, and many time horizons rather than to any single quarter or any single revenue line. Its costs are concentrated. Its deliverables are abstract. Its absence is not visible in the same way a broken CRM is visible. A business leader weighing whether to fund a two-year Enterprise Modeling initiative against a six-month CRM enhancement that demonstrably grows pipeline is making a rational choice when funding the CRM. The Enterprise Model loses the funding battle in most enterprises not because anyone disputes its eventual value but because the structure of business priorities consistently places it behind the revenue work that has hard deadlines and concrete return.
This article addresses the specific reason that pattern has been so stubborn, and what has changed. The reason is the universe of Data Types an Enterprise Model would need to cover — a universe far larger than most people realize when they imagine the modeling work, and one that grows materially each year as enterprises take on more software, more vendors, more compliance scope, more operational complexity, and more cross-cutting governance concerns. What has changed is that two ingredients which were not available a decade ago — the inventories enterprises have steadily built for their own operational needs (which act as instances of specific data types), and AI agents capable of operating on those inventories as a runtime — now make it possible to build and maintain an Enterprise Model in a way the traditional approach cannot. This article walks through the universe, the reason traditional approaches cannot cover it, and the alternative approach that can.
The Vast Universe of Enterprise Data Types, Made Tangible
An Enterprise Model, in the traditional sense, would aim to represent every category of governed thing the enterprise depends on — every kind of asset, every kind of relationship, every kind of artifact, every kind of obligation. The companion IF4IT Enterprise Model and Modeling Best Practices document calls each such category a Noun Type, since each names a kind of thing the enterprise governs. Traditional data modelers may know these as Data Types, Data Entities, or Entity Types; and what the IF4IT calls Noun Types. Throughout the rest of this article the terms are used interchangeably, with Noun Type appearing where the IF4IT terminology is being invoked directly.
To make the scale of the universe tangible, consider what an Enterprise Model would need to cover when an enterprise is decomposed honestly. The categories below are illustrative, not exhaustive — every category named here contains many more Data Types than space allows to enumerate, and the categories themselves are not the only categories that exist. The point is breadth, not completeness.
Core organizational and operational Data Types include Business Units, Legal Entities, Subsidiaries, Org Units, Locations, Buildings, Facilities, Workstations, Cost Centers, Profit Centers, Departments, Teams, Functions, Reporting Relationships, Business Processes, Business Capabilities, Value Streams, Strategic Initiatives, Programs, Projects, Portfolios, Vendors, Suppliers, Partners, Customers, Contracts, Statements of Work, Service Level Agreements, Regulatory Obligations, Policies, Standards, and Procedures. This is the structural core of how an enterprise organizes itself, and it alone runs into the dozens of Data Types before any business domain is even considered.
For enterprise modeling, an enterprise can realize critical core Data Types by using directly mapped Enterprise Inventory Types.
Marketing and Sales Data Types include Customers, Prospects, Leads, Marketing Qualified Leads, Sales Qualified Leads, Opportunities, Deals, Quotes, Orders, Renewals, Subscriptions, Cancellations, Campaigns (with specializations for email, social, paid search, display, event, and account-based marketing), Channels, Touchpoints, Customer Journeys, Personas, Segments, Cohorts, Win/Loss Records, Competitor Records, Channel Partners, Resellers, Marketing Assets, Landing Pages, Forms, Lead Magnets, A/B Tests, Attribution Models, Pipeline Stages, Sales Territories, Quotas, Commissions, Sales Plays, and Battle Cards. The CRM holds some of these; marketing automation platforms hold others; sales operations spreadsheets hold still others; the actual catalog is scattered across systems and disciplines.
Financial Data Types include Chart of Accounts entries, Cost Centers, Profit Centers, GL Codes, Journal Entries, Invoices, Bills, Purchase Orders, Receipts, Payments, Bank Accounts, Bank Transactions, Credit Card Records, Expense Reports, Expense Categories, Budgets, Forecasts, Variances, Accruals, Deferrals, Tax Records, Tax Jurisdictions, Currencies, Exchange Rates, Hedges, Investments, Assets, Asset Categories, Depreciation Schedules, Audit Engagements, Audit Findings, Financial Statements, Regulatory Filings, SOX Controls, and the dozens of master data entities that finance operations depend on. The ERP holds most of these but typically not all of them, and the boundaries between finance and operations consume their own set of Data Types in the seams.
Human Resources Data Types include Employees, Contractors, Consultants, Interns, Candidates, Applications, Interviews, Offers, Positions, Roles, Job Families, Career Ladders, Org Units, Reporting Relationships, Compensation Records, Benefits Records, Equity Grants, Performance Reviews, Goals, OKRs, Competencies, Skills, Certifications, Training Records, Leave Records, Time Records, Onboarding Records, Offboarding Records, Disciplinary Records, Diversity Records, Engagement Surveys, and the many cross-references between HR systems, payroll systems, identity systems, and learning management systems that a real HR practice spans.
Operations and Supply Chain Data Types include Production Orders, Work Orders, Bills of Materials, Routings, Operations, Work Centers, Machines, Tools, Shifts, Production Schedules, Maintenance Records, Quality Inspections, Defects, Returns, Return Merchandise Authorizations, Suppliers (at multiple tiers), Supplier Audits, Purchase Requisitions, Goods Receipts, Inbound Shipments, Outbound Shipments, Carriers, Shipping Routes, Warehouses, Bins, Pick Lists, Pack Lists, Inventory Counts, Cycle Counts, Stockouts, Backorders, and the deep specialization that real manufacturing or distribution operations carry beneath each of these.
Information Technology Data Types are themselves enormous, and worth taking a moment with because they illustrate how specialization multiplies the count. The category includes Computing Devices (with specializations for Servers, Laptops, Desktops, Mobile Devices, Tablets, Embedded Devices, IoT Devices, and Wearables), Network Devices (Routers, Switches, Firewalls, Load Balancers, Access Points, Gateways), Storage Devices (Storage Area Networks, Network Attached Storage, Tape Systems, Disk Arrays), Data Center Racks, Cabling Infrastructure, Power Infrastructure, Cooling Infrastructure, Cloud Resources (Virtual Machines, Containers, Serverless Functions, Kubernetes Clusters), Network Segments, Subnets, VLANs, Software (with specializations for Software-as-a-Service, Open Source, Custom Built, Vendor Installed, Embedded, Mobile Apps, Web Apps, Desktop Apps, APIs, Microservices, Libraries, Frameworks, Operating Systems, Hypervisors, Databases, Middleware, Message Queues, and Caches), Source Code Repositories, Continuous Integration and Deployment Pipelines, Build Artifacts, Container Images, Deployment Environments (Development, Test, Staging, Production, Disaster Recovery), Configurations, Configuration Items, Patches, Releases, and Hotfixes. The IT category alone reaches well into the hundreds of Data Types once specialization is taken seriously, and that count is conservative.
Security Data Types include Threats, Threat Actors, Vulnerabilities, Common Vulnerabilities and Exposures (CVEs), Security Controls, Control Frameworks, Security Incidents, Security Events, Indicators of Compromise, Attack Patterns, Risks, Risk Assessments, Security Policies, Access Roles, Permissions, Identities, Service Accounts, Privileged Accounts, Certificates, Keys, Secrets, Encryption Standards, Compliance Frameworks (NIST, ISO 27001, SOC 2, PCI-DSS, HIPAA, GDPR, and many others), Audit Findings, Remediation Items, Penetration Test Findings, Bug Bounty Reports, and Security Training Items. The Security category is a category many enterprises do not yet have a complete catalog of, even though every Security incident the enterprise faces depends on knowing what is in the catalog.
Data and Information Data Types are a category many enterprises overlook because they have not historically been governed as carefully as physical or financial assets, but they are no less load-bearing for an Enterprise Model. The category includes Data Sources, Data Stores, Data Sets, Data Elements, Data Attributes, Data Models, Data Schemas, Data Pipelines, ETL Jobs, Data Quality Rules, Data Quality Findings, Data Lineage Records, Data Dictionaries, Master Data Records, Reference Data Sets, Data Lakes, Data Warehouses, Data Marts, Data Catalogs, Business Intelligence Reports, Dashboards, KPIs, Metrics, Data Products, Data Domains, Data Contracts, Data Stewardship Records, Data Privacy Classifications, and Data Sensitivity Classifications. As enterprises increasingly recognize data as a governed asset class, this category continues to expand.
Location Data Types extend further than most enterprises notice on first inspection. The category includes Facilities, Buildings, Floors, Rooms, Workstations, Data Centers, Data Center Racks, Server Rooms, Cages, Regions, Sub-regions, Countries, States and Provinces, Cities, Postal Zones, Time Zones, Continents, Geographic Markets, Service Areas, Network Locations, Cloud Regions, and Cloud Availability Zones. Location is one of the cross-cutting dimensions that every other category interacts with — every Employee has a Location, every Facility has a Location, every Cloud Resource has a Location, every Customer Touchpoint has a Location — which means Location Data Types appear in the cross-references of nearly every other category as well.
And then there are industry-specific Data Types, which are where the count begins to escalate sharply. A Healthcare Payer governs Members, Subscribers, Dependents, Plans, Benefits, Claims (Medical, Dental, Pharmacy, Vision, Behavioral Health), Procedures, Diagnoses (using ICD-10 coding), Procedure Codes (using CPT coding), Drug Codes (using NDC coding), Providers (individual and organizational), Networks, Authorizations, Referrals, Appeals, Grievances, Premiums, Cost Shares, Deductibles, Out-of-Pocket Maximums, Explanations of Benefits, Coordination of Benefits Records, Subrogation Records, Care Management Records, Quality Measures (such as HEDIS), Risk Adjustment Records (such as HCC), Encounters, Episodes of Care, Member Communications, Provider Communications, and Regulatory Filings — well over a hundred industry-specific Data Types before the payer’s common enterprise categories are even added. A Life Sciences or Pharmaceutical organization governs Compounds, Drug Substances, Drug Products, Dosage Forms, Strengths, Routes of Administration, Indications, Mechanisms of Action, Targets, Pathways, Clinical Trials (Phases I through IV), Protocols, Protocol Amendments, Investigators, Sites, Subjects, Consent Records, Case Report Forms, Adverse Events (including Serious Adverse Events and Suspected Unexpected Serious Adverse Reactions), Safety Signals, Regulatory Submissions (Investigational New Drug applications, New Drug Applications, Biologics License Applications, Marketing Authorization Applications, supplemental NDAs), Regulatory Agencies, Inspection Records, Manufacturing Lots, Batches, Stability Studies, Specifications, Quality Control Records, Good Manufacturing Practice Records, Validation Records, and the deep supply chain that pharmaceutical operations depend on — again, easily a hundred fifty or more industry-specific Data Types layered on top of the common enterprise core.
When the categories above are decomposed honestly and the cross-cutting dimensions are accounted for, a mature enterprise’s universe of Data Types is genuinely in the low thousands. The specific count varies substantially by industry, by operational complexity, and by the depth of specialization the enterprise chooses to govern. A relatively focused mid-sized enterprise in a single industry may govern in the range of one to two thousand Data Types when all the specialization depth is honestly accounted for. A large diversified or multi-industry enterprise can reach three to five thousand or more. A regulated industry with deep operational specialization — healthcare, life sciences, financial services, energy, defense — reliably reaches the higher end. The number is not exaggerated by counting every minor variation as its own type; it reflects what the enterprise actually has to govern when its operational, financial, regulatory, security, and industry-specific realities are laid out without abbreviation.
This is the vast universe an Enterprise Model would need to cover. Whatever traditional approach an enterprise might use to build that model would have to confront the scale of the universe directly. It is the scale, and not any failure of intent or competence, that has historically defeated those approaches.
Why Traditional Enterprise Modeling Cannot Cover It
The traditional approach to Enterprise Modeling treats the universe of Data Types as a problem to be solved through centralized design. An Enterprise Architecture team or a Data Architecture team takes responsibility for defining each Data Type, its attributes, and its relationships to other Data Types, and for capturing the result in a single integrated model — typically a relational schema, a metamodel inside an Architecture Modeling Tool, or some combination of the two. The model is then governed through a release cycle that introduces new Data Types as the enterprise evolves, retires old ones as they go out of use, and reconciles changes as business priorities shift.
This approach is honest, professional, and intellectually serious. The discipline it requires is real. The people who do it well are skilled practitioners doing important work. The approach fails not because anyone is doing it wrong but because four economic and architectural realities work against it at the scale of the actual universe.
The cost is concentrated and the benefit is diffuse. Modeling thousands of Data Types and their relationships is multi-year, multi-million-dollar work. It requires sustained staffing of senior architects and data modelers, sustained access to subject matter experts across the enterprise, sustained governance, and sustained tooling investment. The benefit, by contrast, accrues across many decisions, many domains, and many time horizons. No single quarter, no single business case, no single executive sponsor carries the full investment. The investment justifies itself only at the scale of the enterprise as a whole and over the timeframe of many years, which is exactly the timeframe and scale at which business cases are hardest to close.
Revenue-data work has hard deadlines; Enterprise Modeling work does not. Marketing has a campaign launching next quarter. Sales has a CRM that goes live in six weeks. Product Management has a feature release date. Customer Support has a ticketing migration. Each of these has a hard deadline, a visible business consequence if it slips, and a clear chain of accountability to a revenue line. Enterprise Modeling work has none of these. The model can always be deferred a quarter, a year, a budget cycle, and the immediate consequences of deferral are invisible. So it is deferred. Across many enterprises and many years, the pattern produces the same outcome — the model never becomes complete because there is never a forcing function strong enough to make it complete.
The model is brittle to the enterprise’s own evolution. Even when an enterprise invests seriously and produces a substantial integrated model, the model begins aging the moment it is published. The enterprise acquires a new subsidiary that brings its own Data Types. A regulation changes the structure of compliance obligations. A new product line introduces new categories. A vendor consolidation collapses several Data Types into one. The cost of maintenance compounds because every change has to be reconciled against the integrated whole. Over time, the gap between the model and the enterprise widens, the model becomes a liability rather than an asset, and the business case for continuing to maintain it becomes harder to defend. Many traditional Enterprise Modeling efforts have ended not with a clean conclusion but with a quiet decision to stop maintaining what no longer reflects reality.
Even if it succeeded, the artifact would not be what AI needs. This is the architectural reality that the economic critique sometimes obscures. A traditional integrated relational model, or a fixed-metamodel artifact inside an Architecture Modeling Tool, is not a Semantic Model in the sense the AI-runtime era now requires. It carries element-type names, property specifications, and relationship definitions, but it typically does not carry the semantic mechanisms — semantic identifiers, semantic relationships, reified semantic relationships, rich attribute content, natural-language rules — that AI as a runtime relies on to interpret a model natively. Even an enterprise that succeeded in completing a traditional model would still have to perform an additional translation effort to make the model AI-consumable. The IF4IT Enterprise Model and Modeling Best Practices document develops this distinction in detail; the relevant point here is that the traditional approach, even when fully successful, would produce an artifact that requires another expensive step before it could deliver the value an AI-coupled Enterprise Model can deliver natively.
These four realities compound. An approach that is expensive, deadline-disadvantaged, brittle to change, and architecturally incomplete cannot, in practice, cover a universe of thousands of Data Types. It cannot do so at any reasonable cost. It cannot do so on any reasonable timeline. And it cannot do so in a form that delivers what AI now makes possible. The Enterprise Model has remained a second-class citizen not because anyone failed to try, but because the traditional approach was never going to succeed against this scale.
Why Using Inventories With AI Changes the Game
The shift that makes a different approach possible is the recognition that two ingredients now exist which were not available a decade ago, and which together resolve the constraints that defeated the traditional approach.
The first ingredient is the inventories the enterprise already has (i.e., Enterprise Inventories). Every enterprise of any maturity owns inventories — lists, catalogs, registers, source systems, governed records — that capture the Noun Instances of many of the Noun Types in the universe. The CRM holds the inventory of Customers, Opportunities, and Accounts. The ERP holds the inventory of Invoices, Purchase Orders, Cost Centers, and General Ledger entries. The Identity Provider holds the inventory of Employees and Service Accounts. The IT Service Management system holds the inventory of Incidents, Changes, Configuration Items, and Service Requests. The Source Code Management system holds the inventory of Repositories, Pipelines, and Releases. The Procurement system holds the inventory of Vendors and Contracts. The Quality Management system holds the inventory of Findings and Remediations. The Risk Register holds the inventory of Risks and Controls. The Marketing Automation platform holds the inventory of Campaigns, Touchpoints, and Audiences. The Product Management system holds the inventory of Products, Features, and Roadmap Items. These inventories already exist because the business funded them for operational reasons — they were built to run the business, not to populate an Enterprise Model, and the business absorbed the cost of building them because the business had to.
This changes the economics of Enterprise Modeling fundamentally. The traditional approach treated the cost of capturing the Noun Instances as part of the Enterprise Modeling investment. The IF4IT EM approach does not. The inventories that hold the Noun Instances are not paid for out of the Enterprise Modeling budget — they are paid for out of the operational budgets that own them, and they exist whether or not an Enterprise Model is being built. The Enterprise Modeling investment now begins from inventories that are already paid for and already in motion, rather than from a blank slate.
The second ingredient is AI capable of operating on those inventories as a runtime. The companion IF4IT Enterprise Model and Modeling Best Practices document develops this in depth across its treatment of AI as the Graph Compiler and AI as the Graph Runtime, but the relevant point here is that AI can now read the inventories the enterprise owns, interpret their semantic content, recognize the Noun Types they represent, identify the relationships between Noun Instances across inventories, and compile the resulting structure into a connected Semantic Model of the enterprise — on demand, in working memory, without any persistent integration step. The compilation work that traditional approaches relied on humans to perform — element-by-element design, relationship-by-relationship reconciliation, attribute-by-attribute mapping — AI can now perform across thousands of Noun Types in minutes, against the inventories the enterprise already governs.
Together, these two ingredients invert the economics of Enterprise Modeling. The investment shifts from a multi-year, multi-million-dollar centralized design effort to a much smaller exercise in describing the inventories the enterprise already owns and the Noun Types they realize. The model grows organically as inventories grow and as new inventories are added — not as a multi-year forward-design exercise but as the natural accumulation of governance work the enterprise was already doing for operational reasons. Maintenance is no longer a brittle reconciliation against an integrated whole; it is a steady evolution of the inventories the enterprise was always going to maintain and of the lightweight model that points to them. And the resulting Enterprise Model is a Semantic Model in the form AI requires — not a translation step away from being AI-consumable, but natively consumable from the moment it exists.
The four constraints that defeated the traditional approach each soften or invert under this approach. The cost is no longer concentrated, because the inventories that carry most of the weight are already paid for and the AI runtime is increasingly inexpensive. The deadline asymmetry no longer matters, because the model grows as the inventories grow rather than requiring a separate forcing function. The brittleness to change no longer compounds, because each inventory evolves under its own Inventory Owner’s discipline rather than requiring reconciliation against an integrated whole. And the architectural incompleteness no longer applies, because the resulting model is a Semantic Model in the form AI was waiting for.
This is the resolution. It does not require an enterprise to abandon its existing investments in modeling tools, data architecture, or enterprise architecture — those continue to do their work where they do it well. It changes the underlying premise about what Enterprise Modeling is, and about what enterprises can now reasonably expect to achieve in this discipline. An Enterprise Model that covers the full universe of Data Types, that scales across every domain space the enterprise operates in, that is maintained at the natural pace of the inventories that realize it, and that is natively consumable by AI from the moment it exists — this is no longer aspirational. It is a discipline an enterprise can practice now.
What the IF4IT Enterprise Model and Modeling Best Practices Document Develops
This article makes the case. The full apparatus of the approach — what the IF4IT Enterprise Model actually is, how it is structured, how it is built, how it is governed, how it is measured, how it scales across domain spaces, and how an enterprise adopts it — lives in the IF4IT Enterprise Model and Modeling Best Practices document. The document is organized around three load-bearing theses (the IF4IT EM as a Semantic Model, AI as the Graph Compiler, and AI as the Graph Runtime) and develops the discipline across the full set of practitioner and leadership concerns that adoption requires.
Several treatments are particularly relevant to the argument this article makes. The document develops the Taxonomy of Noun Types as the model’s domain-space definition construct, including the discipline of scaling the Taxonomy across enterprise, industry, functional, product, operational, and problem-specific domains — which is the discipline that allows the IF4IT EM’s approach to handle the vastness of the universe of Data Types this article has walked through. The document develops the Ontology as the layer that gives each Noun Type its meaning, attributes, relationships, and rules, including the role AI plays in compiling and reasoning over the Ontology at runtime. The document develops the role of the Inventories as the realizing population of each Noun Type, including how existing inventories already owned by Inventory Owners across the enterprise can be brought into the Enterprise Model without a separate integration project. And the document develops the empirical foundation — the non-AI deterministic compiler the IF4IT has built (NOUNZ) and the multi-pilot AI testing across distinct subject matters — that grounds the document’s claims in evidence rather than in aspiration.
The IF4IT Enterprise Model and Modeling Best Practices document is available on if4it.org. It sits alongside the companion IF4IT Enterprise Inventory Management Best Practices document (EIM), which treats the discipline of governing the inventories on which the IF4IT EM depends. Readers whose primary interest is the modeling discipline should start with the IF4IT EM document; readers whose primary interest is the inventory discipline that underlies it should start with EIM. The two documents are designed to be read together.
The Enterprise Model does not have to be a second-class citizen. It became one because the universe of Data Types it would need to cover defeated the traditional approach to building it. That defeat was real and the second-class status it produced was rational — a business leader who declined to fund a multi-year, multi-million-dollar effort that could not realistically succeed was making the right call. What has changed is that an approach now exists that can succeed at the scale of the actual universe, at a fraction of the traditional cost, with quality that compounds rather than erodes over time. The case for funding the Enterprise Model can now be made honestly. The discipline that supports that case is what the IF4IT Enterprise Model and Modeling Best Practices document develops.
Copyright of the International Foundation for Information Technology (IF4IT): 2026 - Present
Back to Articles PageHow to cite this page
When referencing this page in academic work, internal standards, or external publications, include the page title, IF4IT as publisher, the URL, and your access date.
Example (informal web citation):
International Foundation for Information Technology (IF4IT). The Universe Of Enterprise Data Types Is Vast — Why Traditional Enterprise Modeling Cannot Cover It But Inventories And AI Can. https://if4it.org/articles/2026-06-04-the-universe-of-enterprise-data-types-is-vast-but-inventories-and-ai-can-handle-them/ (accessed 2026-06-23).
See About Us for content governance and site-wide citation guidance.