Building and Using Enterprise Knowledge Models with AI-Generated Data Graphs
International Foundation for Information Technology (IF4IT)
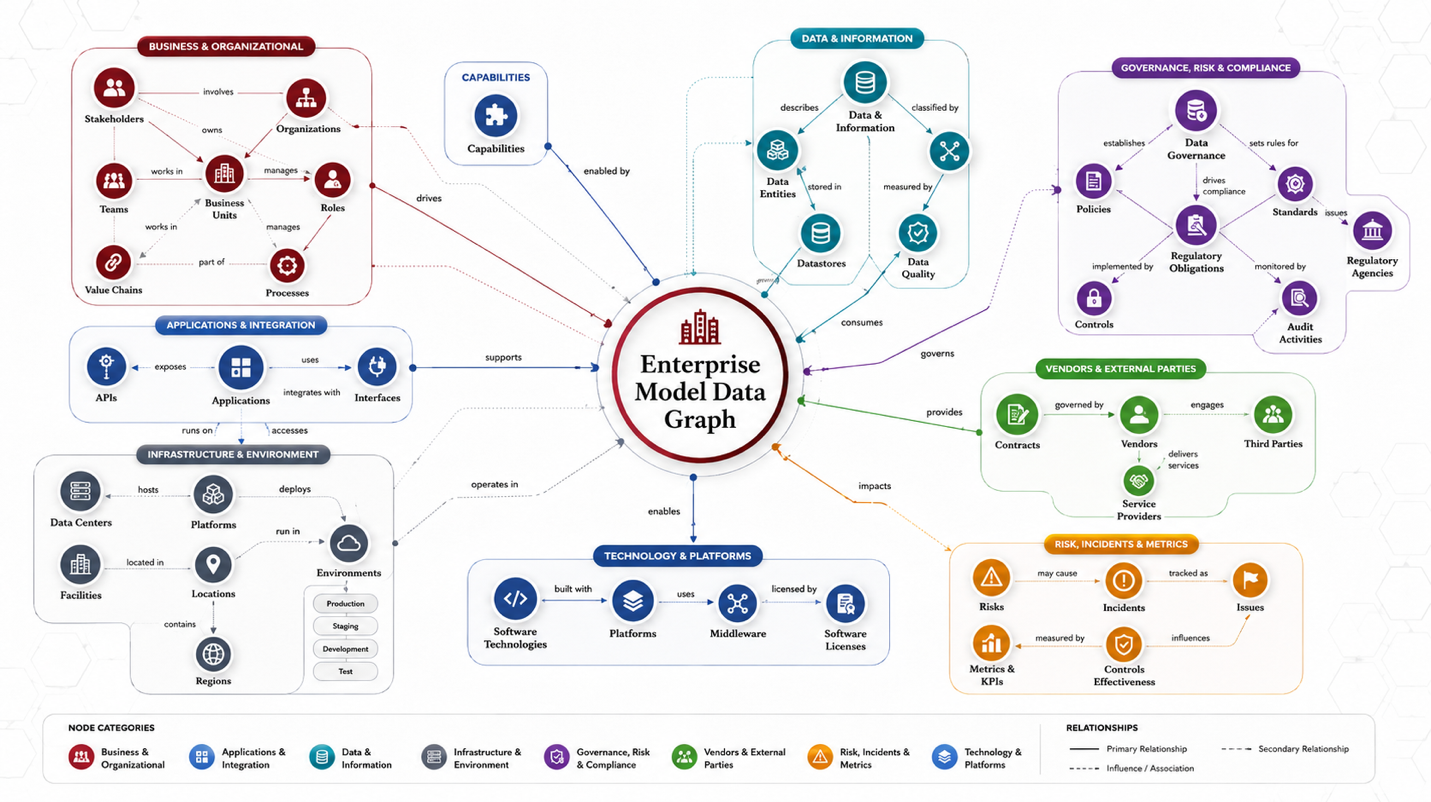
Abstract
Enterprise knowledge is often disjointly scattered across documents, applications, spreadsheets, wikis, tickets, architecture repositories, data catalogs, vendor portals, contracts, policies, and the minds of people who understand how the enterprise really works. Artificial intelligence can help generate, connect, traverse, and reason over this knowledge, but only when the enterprise provides a coherent foundation. This article explains how AI-generated data graphs can be created and used to build and operate Enterprise Knowledge Models. It introduces three dependencies required to make those graphs reliable: 1) a Taxonomy that defines the kinds of things the enterprise recognizes, 2) an Ontology that defines how those things relate, and 3) governed Enterprise Inventories that provide trusted real-world instances. It also explains why AI changes the time-to-value equation by allowing enterprises to assemble useful in-memory working graphs in seconds or minutes, rather than waiting months or years for traditional human-heavy modeling and ETL efforts. Finally, it clarifies that AI can act as both the compiler that assembles the graph and the runtime environment that queries, traverses, visualizes, reasons over, and explains the graph, while governance determines what becomes authoritative.
Figure: A conceptual representation of a small Enterprise Knowledge Model that is based on a Data Graph.
The Problem: Enterprise Knowledge Is Everywhere, but Not Always Connected
Most enterprises have enormous amounts of knowledge. They know their applications, business capabilities, contracts, vendors, systems, data stores, regulatory obligations, teams, processes, projects, products, services, risks, controls, and stakeholders. However, this knowledge is usually distributed across many places and managed by many different groups.
A contract team may maintain contract records. An architecture team may maintain application records. A security team may maintain control and risk records. A data governance team may maintain data catalogs. A vendor management team may maintain vendor records. A compliance team may maintain regulatory mappings. A service management team may maintain incident and change data. Business teams may maintain process knowledge in documents, presentations, spreadsheets, and collaboration tools.
Each knowledge source may be useful on its own. The problem is that the enterprise often cannot reason across them.
It may not be able to easily answer questions such as:
Which applications support this business capability?
Which vendors support those applications?
Which contracts govern those vendors?
Which data stores are used by those applications?
Which regulations impose obligations on those data stores?
Which controls satisfy those obligations?
Which stakeholders are affected if one of those systems changes?
Which risks increase if a vendor, application, data source, or regulation changes?
These are not merely technical questions. They are enterprise knowledge questions. They require a model of the enterprise that connects things, meanings, relationships, and real instances.
This is where Enterprise Knowledge Models and AI-generated data graphs become powerful.
What Is an Enterprise Knowledge Model?
An Enterprise Knowledge Model is a structured representation of the things an enterprise cares about, how those things are defined, how they relate, and which real-world instances exist.
It is not simply a document library. It is not simply a data catalog. It is not simply an architecture repository. It is not simply a knowledge base. Those may all contribute to it, but the model itself is broader.
An Enterprise Knowledge Model allows humans and AI systems to reason over the enterprise as a connected whole.
At minimum, it requires three dependencies:
Taxonomy - the set of Noun Types the enterprise recognizes.
Ontology - the meanings, relationships, and rules that explain how those Noun Types relate.
Enterprise Inventories - the governed collections of real instances that populate the model.
When those dependencies are present, AI can help compile the model into a data graph or knowledge graph. Once compiled, AI can act as a runtime environment for the graph by traversing it, querying it, summarizing it, visualizing it, comparing related concepts, reasoning over it, and generating useful outputs from it.
Without those dependencies, AI may still generate a graph, but the graph may be inconsistent, incomplete, hard to validate, and difficult to govern.
Why AI-Generated Data Graphs Matter
AI-generated data graphs matter because they can turn scattered enterprise knowledge into connected, usable enterprise intelligence. More importantly, AI can do it faster, better, and cheaper than an army of humans can.
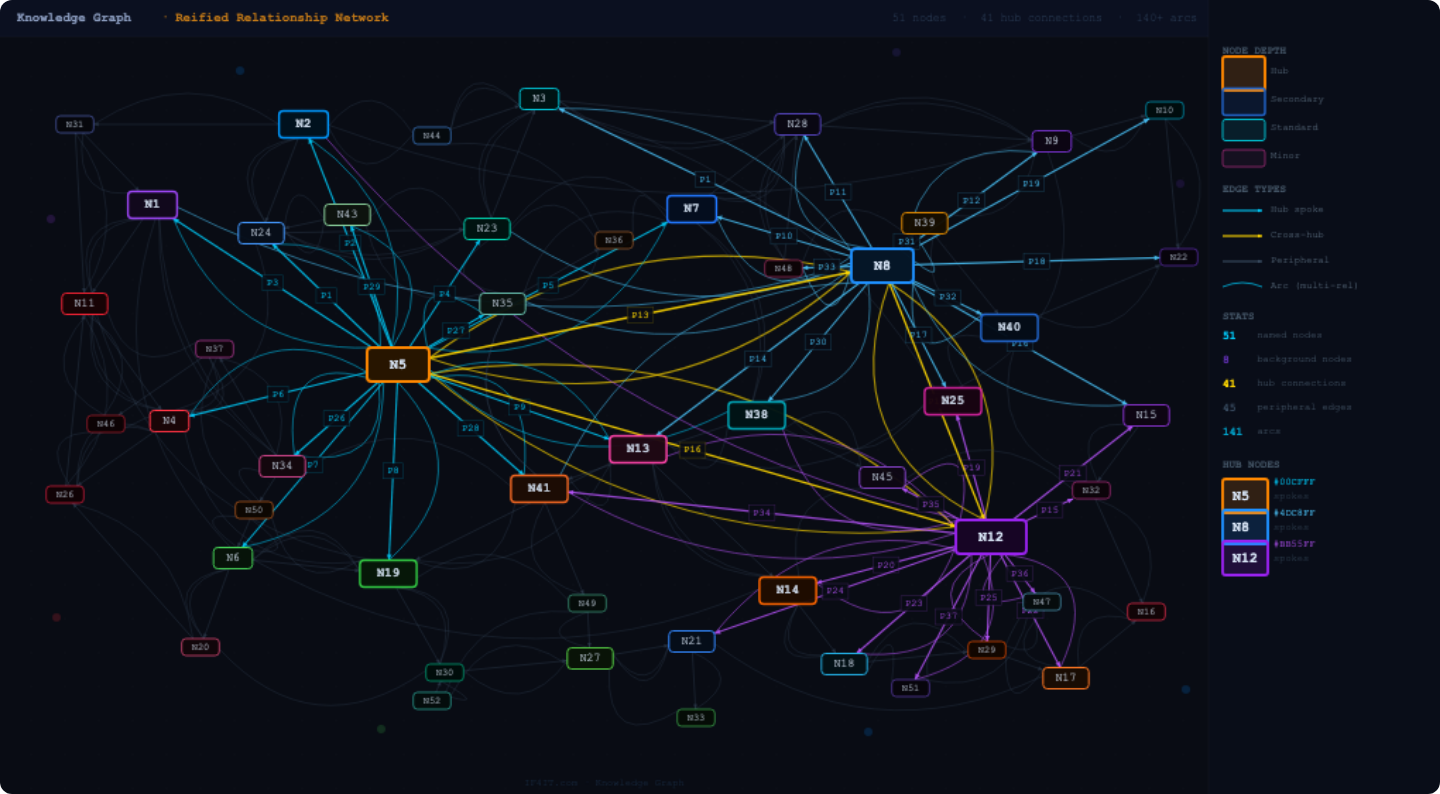
Figure: A conceptual representation of a Data Graph that is composed of Described Nodes and Relationships between such Nodes.
A data graph represents things as nodes and relationships as edges. For example, an Application can support a Capability. A Vendor can provide a Product or Service. A Contract can govern a Vendor. A Data Store can contain Data and Information. A Regulation can impose a Regulatory Obligation. A Control can satisfy an Obligation. A Stakeholder can own, use, approve, or be affected by a Noun Instance.
When these relationships are represented as a graph, the enterprise can ask richer questions.
Instead of asking only, “What applications do we have?” the enterprise can ask, “Which high-criticality applications support customer-facing capabilities, rely on third-party vendors, process regulated data, and have contracts expiring in the next twelve months?”
Instead of asking only, “What regulations apply?” the enterprise can ask, “Which regulatory obligations affect data used by customer-facing systems in a specific jurisdiction, and which controls provide evidence that those obligations are being met?”
Instead of asking only, “What systems might be impacted by a change?” the enterprise can ask, “Which stakeholders, applications, vendors, contracts, data stores, obligations, controls, risks, and business capabilities may be affected by this change?”
AI can help create the graph by extracting candidate entities, identifying relationships, normalizing terminology, suggesting classifications, comparing records, filling gaps, and producing visualizations. AI can also use the graph interactively as a runtime environment that helps people traverse relationships, ask questions, perform impact analysis, explain dependencies, and generate operational outputs.
However, AI should not invent the enterprise model from nothing. It should operate against a governed foundation.
That foundation begins with Taxonomy, Ontology, and governed Enterprise Inventories.
Why AI Changes the Time-to-Value Equation
AI changes the time-to-value equation for Enterprise Knowledge Models.
Historically, building a useful enterprise data graph required long human-driven cycles of modeling, source analysis, data collection, transformation, loading, reconciliation, mapping, and visualization. Teams had to define the model, locate sources, interpret inconsistent records, build custom ETL pipelines, normalize data, create relationships, validate results, and then repeat much of the process whenever the enterprise changed.
This work could take months or years because it was constrained by two human-limited functions.
First, the modeling function was slow. People had to decide which enterprise Noun Types mattered, define their meanings, identify relationships, resolve semantic ambiguity, determine the right levels of abstraction, and decide how the model should represent real enterprise complexity.
Second, the data-loading function was slow. Traditional integration approaches often required custom ETL work for each source, each schema, each transformation rule, and each target structure. Every new source, relationship, exception, reconciliation rule, and quality issue could become another technical implementation effort.
AI does not eliminate the need for disciplined modeling or governed inventories, but it can dramatically compress the exploratory cycle. An AI system can ingest documents, spreadsheets, exports, diagrams, contracts, policies, tickets, metadata, inventory records, architecture artifacts, data catalogs, and other enterprise content. It can identify candidate entities, infer candidate relationships, normalize terminology, detect duplicates, summarize gaps, and assemble an in-memory data graph in seconds or minutes.
That provisional graph can then be queried, visualized, challenged, corrected, and refined by humans.
This is a major shift. Instead of waiting months for a fully engineered data integration pipeline before seeing value, the enterprise can use AI to create an initial working model quickly, learn from it, identify what matters, and then decide which parts should be promoted into governed inventories, authoritative relationships, reusable pipelines, or formal Enterprise Model structures.
The time savings are not limited to graph creation. AI can also accelerate the first analytical use of the graph. Once the working graph exists in AI memory or in a graph-access environment, AI can immediately help traverse it, summarize it, explain it, compare nodes, surface gaps, and test hypotheses.
The distinction is important: AI can quickly generate and use a working graph, but governance determines what becomes trusted and authoritative.
A working graph may be good enough for exploration, discovery, impact analysis, hypothesis testing, gap identification, brainstorming, scenario modeling, or executive visualization. An authoritative Enterprise Model requires review, stewardship, validation, source traceability, inventory ownership, lifecycle management, and evidence.
The value of AI-generated data graphs is therefore not that they remove enterprise modeling discipline. The value is that they accelerate discovery, reduce initial friction, expose hidden relationships, shorten the path from scattered enterprise knowledge to usable enterprise insight, and speed the first meaningful use of that insight.
Dependency 1: Taxonomy
A Taxonomy defines the kinds of things the enterprise recognizes.
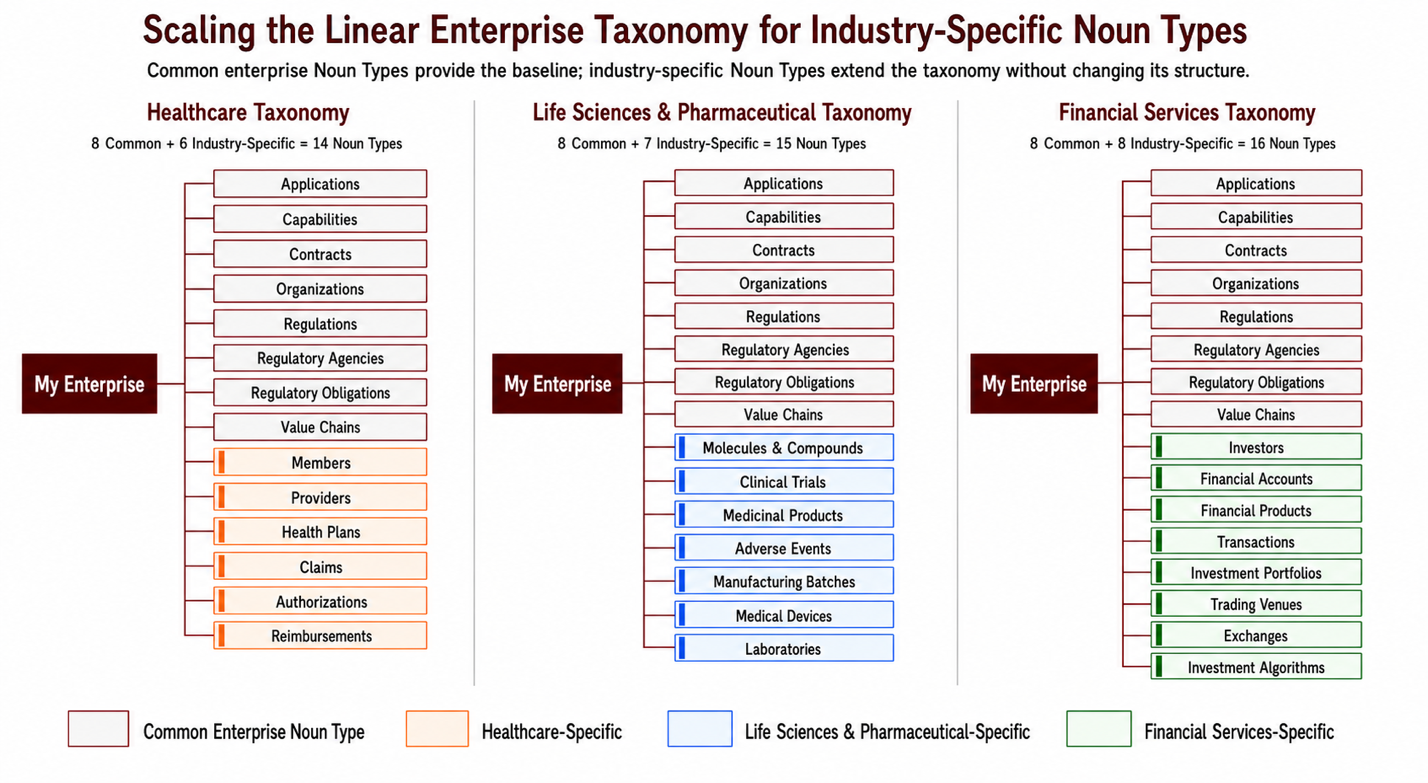
Figure: Three separate industry-specific taxonomy examples using a limited set of common and different Noun Types.
In IF4IT terminology, these kinds of things are often treated as Noun Types. Examples include Applications, Capabilities, Organizations, Contracts, Vendors, Data Stores, Regulations, Regulatory Obligations, Software Technologies, Software Licenses, Data Centers, Facilities, Business Processes, Stakeholders, Controls, Risks, and Evidence Records.
The Taxonomy gives AI and people a shared vocabulary. It defines what kinds of nodes may appear in the enterprise graph.
Without a Taxonomy, AI may use inconsistent labels for the same concept. One source may refer to “systems,” another to “applications,” another to “platforms,” and another to “solutions.” Some of those terms may be synonyms. Others may represent distinct Noun Types. The enterprise needs a way to decide.
A Taxonomy does not need to be perfect on day one. It can begin with a practical set of common enterprise Noun Types and expand over time. It can also be specialized by domain. A healthcare enterprise may add Members, Providers, Claims, Authorizations, and Reimbursements. A life sciences or pharmaceutical enterprise may add Molecules, Clinical Trials, Medicinal Products, Adverse Events, Manufacturing Batches, Medical Devices, and Laboratories. A financial services enterprise may add Investors, Financial Accounts, Transactions, Investment Portfolios, Exchanges, and Investment Algorithms.
The important point is that the enterprise must know what types of things it is trying to model.
Taxonomy answers the question:
What kinds of enterprise things exist and need to be recognized?
Dependency 2: Ontology
If Taxonomy defines the kinds of things that exist, Ontology defines what those things mean and how they relate.
An Ontology describes the relationships, rules, meanings, and semantic structures that make the model useful. It helps answer questions such as:
Can an Application support one or many Capabilities?
Can a Vendor provide one or many Services?
Can a Contract govern multiple Vendors or Vendor Services?
Can a Regulation impose many Regulatory Obligations?
Can a Control satisfy more than one Obligation?
Can a Data Store be used by multiple Applications?
Can a Stakeholder own, approve, use, or be affected by different Noun Instances?
Ontology matters because relationships are where enterprise knowledge becomes useful. A list of applications is useful, but a graph of applications, capabilities, vendors, data stores, contracts, risks, obligations, controls, and stakeholders is far more powerful.
Ontology also prevents the graph from becoming a collection of arbitrary AI-generated associations. It gives AI guidance about which relationships are meaningful, which relationship names are acceptable, which direction relationships should point, which relationship attributes matter, and when a relationship itself needs to be governed.
For example, the relationship between an AI Agent and an API may need attributes such as allowed actions, effective date, approval status, control requirements, review frequency, and evidence. In that case, the relationship may need to be treated as a governed relationship record, not merely a simple edge.
Ontology answers the question:
What do these enterprise things mean, and how are they allowed to relate?
Dependency 3: Enterprise Inventories
Taxonomy and Ontology define the model structure. Enterprise Inventories populate it with real instances.
An inventory is a governed collection of instances of a defined type. The Application Inventory contains real applications. The Contract Inventory contains real contracts. The Vendor Inventory contains real vendors. The Regulation Inventory contains real regulations. The Regulatory Obligation Inventory contains real obligations. The Control Inventory contains real controls. The Data Store Inventory contains real data stores.
Enterprise Inventories make the model operational.
A Taxonomy may define “Application” as a Noun Type, but the Application Inventory identifies the actual applications the enterprise uses. An Ontology may define that Applications support Capabilities, but inventory relationships identify which actual applications support which actual capabilities. A Regulation may impose an obligation, but the Regulatory Obligation Inventory identifies the specific obligation, owner, applicability, controls, and evidence.
This is where many enterprise knowledge efforts fail. They create models, diagrams, taxonomies, or concept maps, but they do not maintain the underlying inventories. The result is a model that looks meaningful but cannot be trusted for operational decision-making.
Governed inventories require ownership, lifecycle state, currency, quality, classification, source traceability, and stewardship. They must be maintained over time. They must be connected to related inventories. They must be accurate enough for the decisions they support.
Enterprise Inventories answer the question:
What real instances exist, who owns them, how current are they, and how do they relate?
How the Pattern Works
The pattern is straightforward.
- Taxonomy defines the Noun Types.
The enterprise identifies the kinds of things it wants to model in the Taxonomy, such as Applications, Capabilities, Contracts, Vendors, Data Stores, Regulations, Regulatory Obligations, Controls, Risks, Stakeholders, and Evidence Records.
- Ontology defines the relationships.
The enterprise defines how those Noun Types relate, such as Applications support Capabilities, Vendors provide Services, Contracts govern Vendors, Regulations impose Obligations, Controls satisfy Obligations, and Evidence Records prove Controls operated.
- Enterprise Inventories provide the instances.
The enterprise populates the model with real applications, real capabilities, real contracts, real vendors, real regulations, real obligations, real controls, and real evidence records.
- AI Compiles the Graph
AI can help extract, classify, normalize, deduplicate, connect, validate, and enrich candidate graph content from documents, spreadsheets, exports, diagrams, contracts, policies, tickets, metadata, inventory records, architecture artifacts, data catalogs, and other enterprise sources. In this role, AI acts as a graph compiler. It helps transform scattered enterprise data and information into candidate nodes, relationships, classifications, attributes, and graph structures.
This does not mean that every AI-generated node or relationship becomes authoritative. The compilation process should produce a working graph that can be reviewed, challenged, corrected, and refined. Human review, stewardship, source traceability, and governance determine which graph elements should be promoted into governed inventories, authoritative relationships, reusable pipelines, or formal Enterprise Model structures.
- AI Acts as the Runtime Environment for the Graph
Once a working graph exists, AI can also act as a runtime environment for using it. In this role, AI helps traverse the graph, answer questions, perform impact analysis, identify gaps, summarize patterns, explain relationships, generate dashboards, create visualizations, and produce operational outputs. It accomplishes these things by acting as the User Interface where it can easily handle natural language interactions and also generate highly interactive visual constructs (e.g., charts, graphs, heatmaps, dashboards, collapsable & expandable trees, node diagrams, schematic diagrams, data flow diagrams, dependency diagrams, and much more). This means you don’t need a team of User Experience (UX) developers and software developers to build out and maintain complex applications with user interfaces unless you believe it worth doing so.
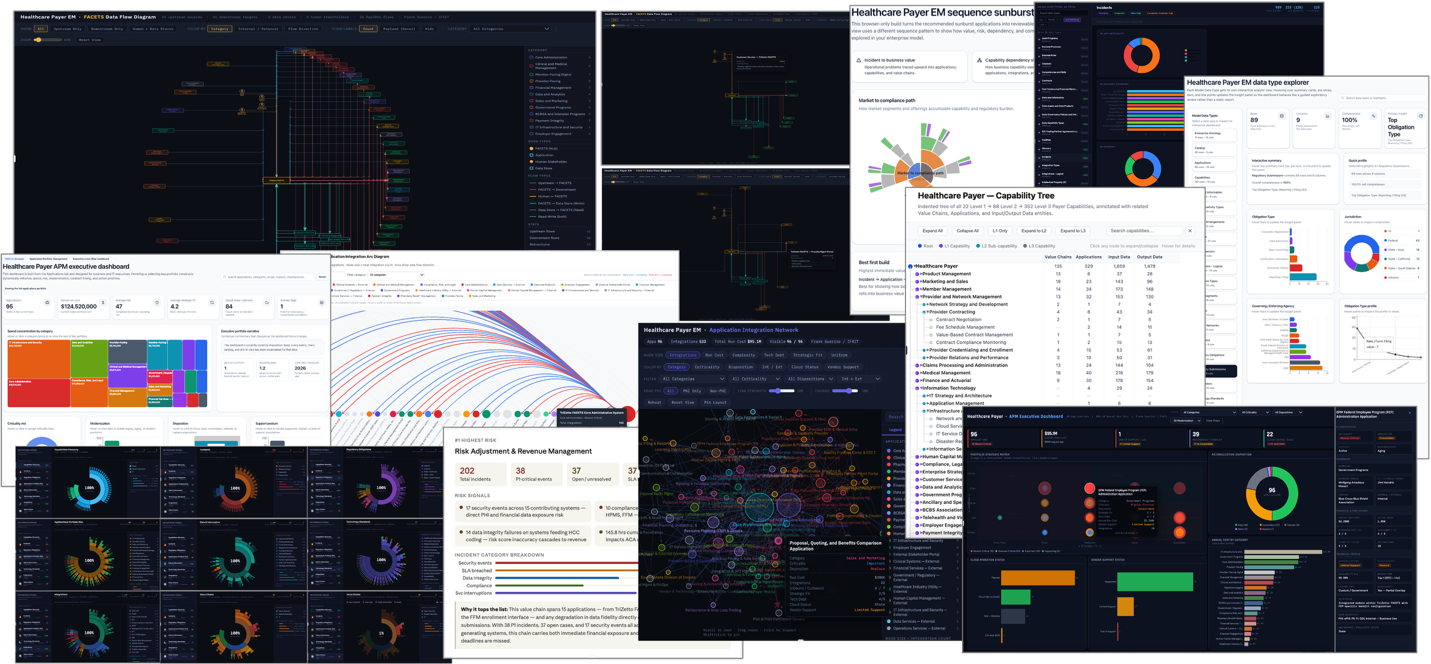
Figure: AI-synthesized, interactive, visual knowledge constructs resulting from an AI-synthesized Enterprise Model.
Using AI as the runtime environment establishes a feedback loop for continuous evaluation and improvement. As AI and humans use the graph, they both may detect missing relationships, inconsistent names, duplicate records, stale inventory items, weak classifications, or candidate obligations. Human review and governance can work together to decide which AI-suggested improvements should be accepted into the authoritative model.
IMPORTANT: The enterprise should treat AI as both an accelerator and a reasoning engine, but not as an uncontrolled authority. AI can compile and use the graph quickly, and it can even generate new data and information from existing data and information quickly, but human governance determines what becomes trusted, authoritative, and operationally binding.
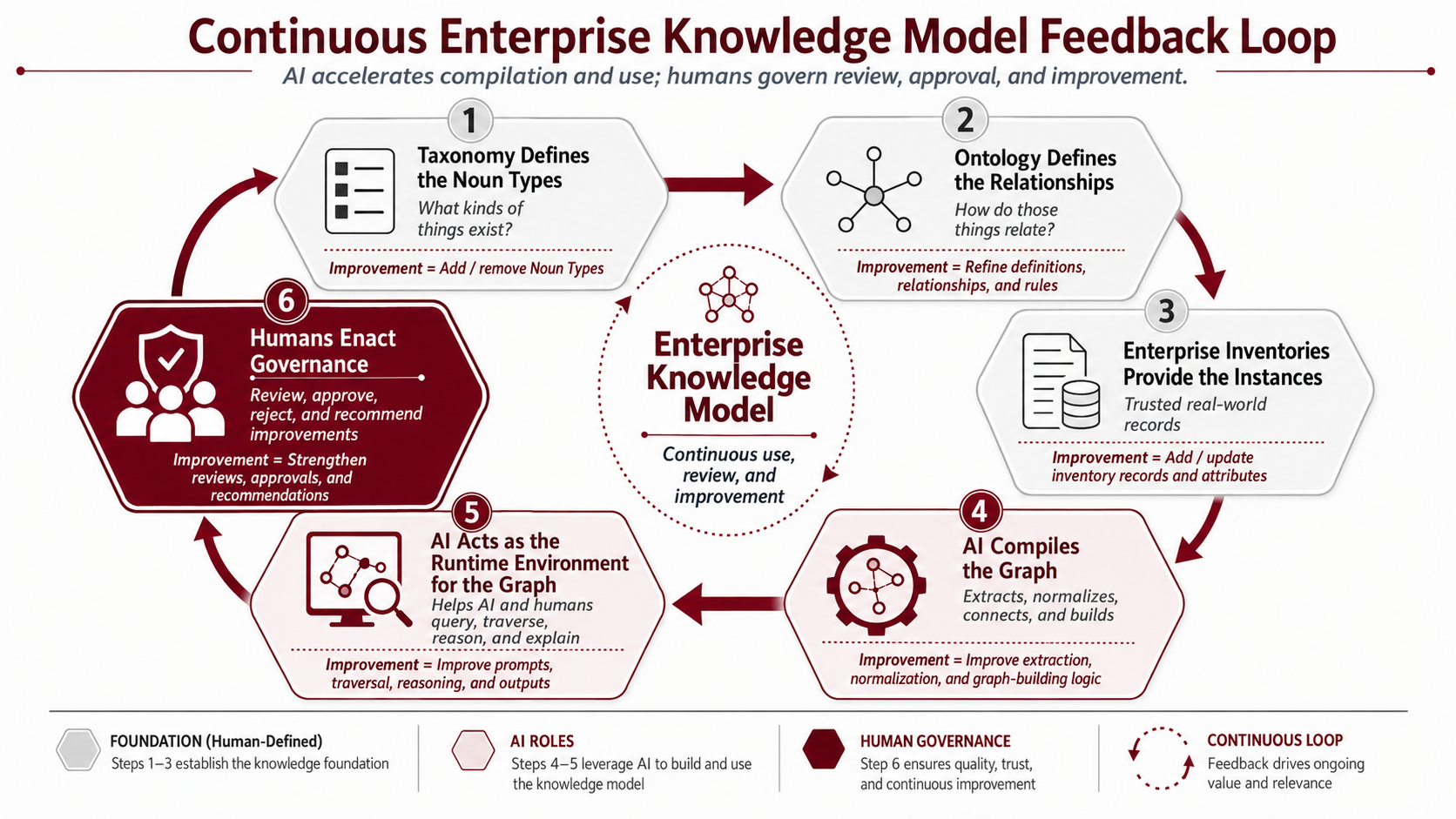
Figure: Continuous improvement of the Enterprise Knowledge Mode using the IF4IT modeling pattern.
The Working Graph and the Authoritative Model
AI-generated data graphs create an important distinction between a working graph and an authoritative model.
A working graph is a fast, AI-generated representation of candidate entities and relationships. It may be built from documents, spreadsheets, exports, diagrams, tickets, contracts, inventories, metadata, and other available enterprise information. It may live temporarily in AI memory or in a graph-access environment. It can be useful almost immediately because it allows people to see patterns, ask questions, test assumptions, and identify gaps.
An authoritative model is different. It is governed. It contains approved Noun Types, validated relationships, stewarded inventory records, trusted sources, ownership, lifecycle states, evidence, and change controls.
Both are valuable, but they serve different purposes.
The working graph accelerates discovery and learning. The authoritative model supports accountable decision-making, compliance, governance, operations, and automation.
The enterprise should use AI to generate and use working graphs quickly, then use governance to decide which entities, relationships, and insights should be promoted into authoritative inventories and model structures.
This makes AI practical without making it reckless.
Why This Matters for Knowledge Management
Knowledge Management often focuses on capturing, organizing, and sharing knowledge through documents, portals, articles, search, communities, and collaboration platforms. Those are valuable, but they do not fully solve the enterprise knowledge problem.
Documents explain. Inventories identify. Ontologies connect. Data graphs allow reasoning.
A knowledge article may describe a process. An inventory record identifies the actual process instance. A relationship connects that process to applications, roles, data, risks, controls, vendors, and obligations. A graph allows the enterprise to ask questions across all of them.
This is where Knowledge Management becomes more operational.
Instead of only asking, “Where is the document that explains this?” the enterprise can ask:
What does this process depend on?
Which applications execute it?
Which data does it use?
Which roles own or perform it?
Which risks are associated with it?
Which regulations affect it?
Which controls protect it?
Which evidence proves it works?
Which changes may impact it?
AI can help answer these questions, but only if the underlying enterprise knowledge is structured enough to reason over.
Knowledge Management becomes more powerful when it is grounded in a governed Enterprise Knowledge Model.
Why This Matters for Enterprise Architecture and Governance
Enterprise Architecture and governance functions have long tried to create connected views of the enterprise. The challenge has been cost, currency, participation, and usability. Models are often hard to populate, hard to keep current, and hard for non-specialists to consume.
AI changes that equation.
AI can help gather candidate model content from documents, inventories, diagrams, spreadsheets, repositories, contracts, policy documents, architecture records, service-management records, and data catalogs. As a compiler, AI can help suggest entities and relationships. As a runtime environment, AI can generate views for different audiences, explain the model in natural language, answer impact-analysis questions, and translate graph content into reports, summaries, dashboards, and planning outputs.
However, AI also increases the need for governance. The easier it becomes to generate and use a graph, the more important it becomes to know whether the graph is reliable.
The enterprise must be able to distinguish between:
AI-suggested graph content
Human-reviewed graph content
Authoritative inventory records
Draft relationships
Validated relationships
Retired or stale model content
Evidence-backed model content
This is why AI-generated data graphs should be treated as part of a governed modeling lifecycle, not as disposable diagrams.
A Practical Starting Point
An enterprise does not need to model everything at once.
A practical starting point is to choose a small set of Noun Types that matter for a real business problem. For example:
Applications
Capabilities
Vendors
Contracts
Data Stores
Regulations
Regulatory Obligations
Controls
Stakeholders
Then define a small set of relationships:
Applications enable Capabilities.
Vendors provide Services.
Vendors sell Software Technologies.
Contracts govern Vendors.
Applications use Data Stores.
Regulations impose Regulatory Obligations.
Controls satisfy Regulatory Obligations.
Stakeholders own or are affected by Noun Instances.
Then populate the inventories with real records.
Then use AI to compile a working data graph, visualize the relationships, identify gaps, and answer practical questions. The same AI environment can then be used as the runtime environment for traversing the graph, testing scenarios, generating summaries, and producing decision-support outputs.
The first graph does not need to be perfect. It needs to be useful, reviewable, and improvable.
Over time, the enterprise can expand the Taxonomy, refine the Ontology, improve inventory quality, add relationship attributes, introduce evidence, automate graph refresh, and mature the runtime uses of the model.
The Risk of Skipping the Foundations
AI-generated data graphs can look impressive even when they are not reliable.
If there is no Taxonomy, the graph may contain inconsistent node types. If there is no Ontology, the graph may contain weak or meaningless relationships. If there are no governed inventories, the graph may be populated with stale, duplicated, incomplete, or unapproved instances.
This creates a dangerous pattern: the graph appears intelligent, but the enterprise cannot trust it.
A graph without governance can amplify confusion. A graph with governed Taxonomy, Ontology, and inventories can amplify understanding.
The difference is discipline.
Learn More
This article introduces how AI-generated data graphs can help enterprises build and use Enterprise Knowledge Models more quickly. Readers who want deeper guidance on Taxonomy, Ontology, semantic modeling, relationship modeling, AI graph compilation, and AI graph runtime behavior should review The IF4IT Enterprise Model and Modeling Best Practices.
Readers who want deeper guidance on governed inventories, inventory ownership, lifecycle management, quality, integration, stewardship, and authoritative enterprise records should review Enterprise Inventory Management Best Practices.
Together, these two best-practice documents explain how enterprises can move from scattered knowledge to governed knowledge, from governed knowledge to AI-generated data graphs, and from AI-generated data graphs to better decisions, stronger governance, and more reliable enterprise understanding.
Closing Thought
AI does not eliminate the need for enterprise knowledge discipline. It increases the value of that discipline.
The enterprises that benefit most from AI-generated data graphs will not be the ones that simply ask AI to draw connections. They will be the ones that define what kinds of things matter, govern what those things mean, maintain trusted inventories of real instances, and use AI to compile, run, traverse, improve, and reason over the resulting model.
Taxonomy gives the enterprise a vocabulary.
Ontology gives the enterprise meaning.
Inventories give the enterprise trusted facts.
AI-generated data graphs turn those elements into a living knowledge model the enterprise can use.
AI can act as both the compiler and the runtime environment for an Enterprise Knowledge Model, while governance determines what becomes trusted, authoritative, and operationally binding.
Back to Articles PageHow to cite this page
When referencing this page in academic work, internal standards, or external publications, include the page title, IF4IT as publisher, the URL, and your access date.
Example (informal web citation):
International Foundation for Information Technology (IF4IT). Building and Using Enterprise Knowledge Models with AI-Generated Data Graphs. https://if4it.org/articles/2026-06-14-building-and-using-enterprise-knowledge-models-with-ai-generated-data-graphs/ (accessed 2026-06-23).
See About Us for content governance and site-wide citation guidance.