Enterprise AI Governance Best Practices - Govern the Data and Information That Feeds AI
Enterprise AI Governance Best Practices
Chapter 22. Govern the Data and Information That Feeds AI
Executive Summary: Chapter Overview
IF4ITThe Bottom Line
Core Concepts
| Concept | Definition & Strategic Role |
|---|---|
| AI Data Dependency | The relationship between AI capabilities and the structured, semi-structured, or unstructured data they consume, retrieve, generate, or affect. |
| Data Boundary | A rule or control defining which data may or may not be used with a specific AI capability, tool, vendor, model, prompt, user group, or location. |
| Data Provenance | The ability to trace which data, documents, records, or retrieved sources influenced AI outputs or actions. |
Quick Q&A
Question: Why does data governance become more complex when AI is introduced?
Question: What should AI data controls answer?
Read More Below
Why AI Data and Information Governance Matters
AI depends on data and information.
AI may use data for training, fine-tuning, retrieval, prompting, inference, summarization, classification, recommendation, generation, evaluation, monitoring, reporting, and evidence. The quality, sensitivity, provenance, location, permission, and governance of that data directly affect AI value and AI risk.
Poorly governed data can cause AI to expose confidential information, produce biased outputs, hallucinate, generate misleading recommendations, violate privacy obligations, misuse regulated data, repeat stale content, amplify errors, or act on incomplete context.
Enterprise AI Governance must govern the data and information that feeds AI. This does not replace data governance. It extends data governance into the specific patterns by which AI consumes, transforms, reasons over, retrieves, generates from, and exposes information.
AI Input Data as a Governed Concept
AI Input Data is any data, information, content, context, metadata, signal, record, document, prompt material, retrieval source, or user-provided input that is used by an AI capability.
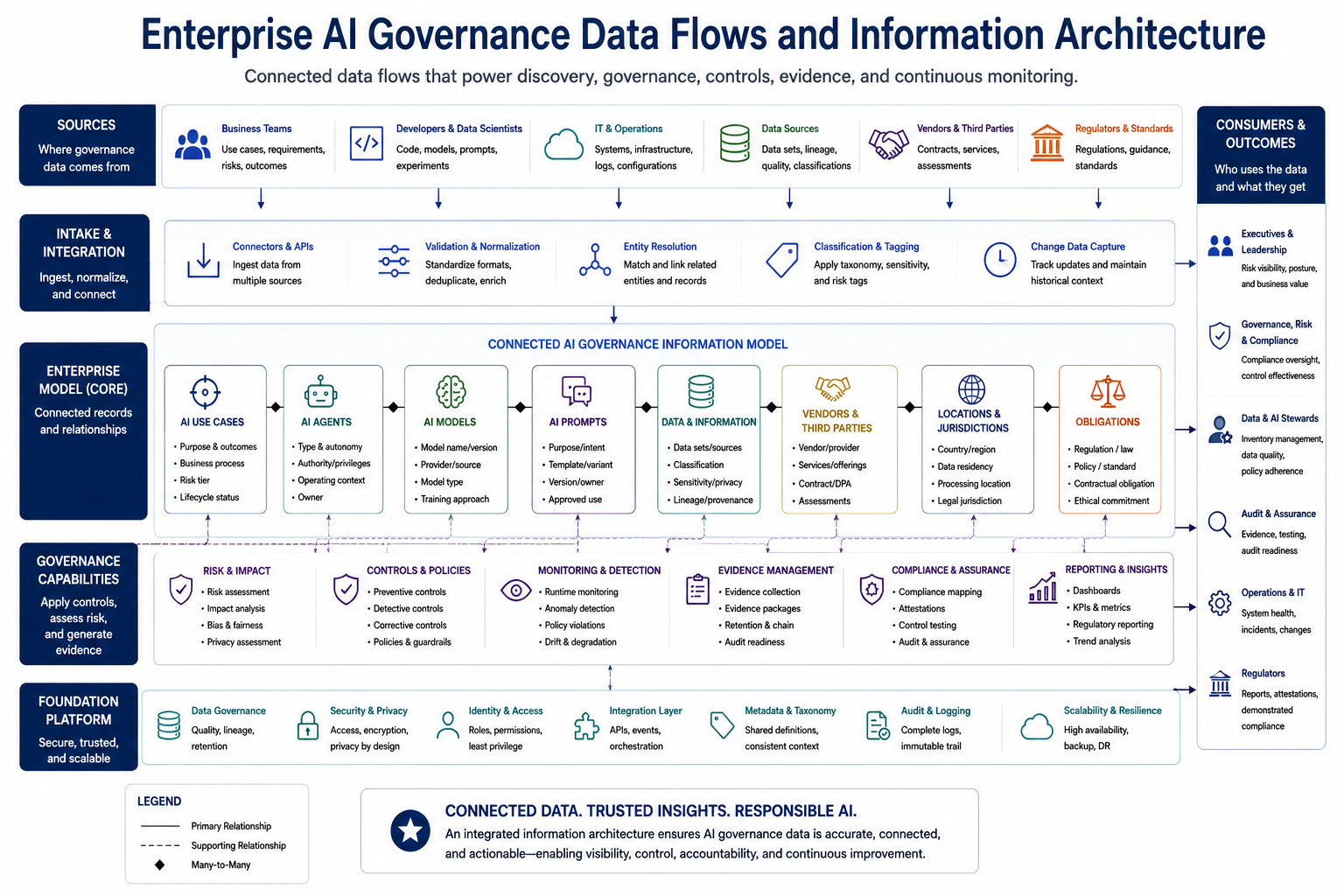
Figure: Enterprise AI Governance Data Flows and Information Architecture
AI Input Data may include structured data, unstructured documents, emails, chat transcripts, tickets, logs, source code, contracts, policies, knowledge articles, customer records, employee records, financial records, medical information, product data, images, audio, video, metadata, operational signals, system context, or real-time user input.
The enterprise should not treat AI Input Data as an informal detail. AI Input Data should be connected to governed Data and Information inventories, data owners, data stewards, data sensitivity classifications, data quality measures, lineage, residency requirements, retention rules, access controls, and approved use policies.
The AI governance question is not only whether data exists. It is whether AI is allowed to use that data for the intended purpose, under the intended conditions, in the intended locations, with the intended controls.
RAG Corpora and Knowledge Sources
Retrieval-Augmented Generation, or RAG, makes knowledge-source governance especially important.
A RAG-enabled AI capability retrieves information from approved or configured sources and uses that information to shape outputs. The quality of the AI output depends heavily on the quality, relevance, currency, completeness, and permissioning of the retrieval corpus.
A RAG corpus may include policy documents, procedures, knowledge articles, product manuals, customer-service content, contracts, regulatory materials, code repositories, design documents, architecture records, incident records, tickets, meeting notes, or other enterprise content.
The enterprise should govern RAG corpora as first-class AI governance assets or as governed relationships to existing knowledge and data inventories. It should know which sources are included, who owns them, how they are curated, how often they are refreshed, what sensitivity they carry, which users or agents may access them, which locations they apply to, and how stale or incorrect content is detected and corrected.
A well-governed model can still produce poor outputs if the retrieval corpus is stale, incomplete, biased, unauthorized, or irrelevant.
Data Sensitivity and Permitted Use
The enterprise must classify the sensitivity of data used by AI.
Sensitive data may include personal information, employee information, customer information, health information, financial information, confidential business information, legal information, security information, intellectual property, source code, trade secrets, regulated data, privileged information, and data subject to contractual restrictions.
Sensitivity classification should influence whether AI may use the data, which AI tools may process it, whether vendor AI is allowed, whether data may leave enterprise-controlled environments, whether human review is required, whether outputs must be retained, whether disclosures are required, and whether additional controls are needed.
The enterprise should distinguish between data that may be used for prompting, data that may be used for retrieval, data that may be used for training or fine-tuning, data that may be used for evaluation, and data that may be included in outputs. These are different uses and may require different permissions.
Data Lineage and Provenance
AI governance requires data lineage and provenance.
The enterprise should know where AI Input Data came from, who owns it, which system or source maintains it, when it was last updated, how it was transformed, whether it was approved for AI use, and how it reached the AI capability.
For RAG and knowledge-based systems, provenance should also identify which source materials influenced an output where feasible. This is important for validation, review, correction, audit, and evidence.
Lineage becomes especially important when AI outputs are used for regulated, customer-facing, employee-impacting, or high-risk purposes. If the enterprise cannot trace an output back to source information, it may not be able to explain, correct, or defend that output.
Data Quality, Currency, and Fitness for Purpose
AI governance must consider whether data is fit for the intended AI use.
Data quality issues can include incompleteness, inaccuracy, duplication, inconsistency, bias, outdated content, poor labeling, unclear provenance, conflicting sources, missing metadata, or unapproved transformations. These issues can produce poor AI outputs even when the model and AI Prompt are well designed.
Currency also matters. AI may retrieve old policy, outdated procedures, expired rates, superseded product information, stale regulatory guidance, obsolete architecture diagrams, retired code examples, or closed incident records. If stale content remains in the retrieval path, AI can produce outputs that appear authoritative but are no longer valid.
The enterprise should define data quality and currency expectations for AI use. Higher-risk use cases require stronger data-quality controls, source validation, review cycles, freshness rules, and remediation processes.
Data Residency, Transfer, and Location
AI data governance must include data residency, transfer, and location.
AI may process data in one region, store logs in another, invoke a model hosted elsewhere, retrieve content from a cloud region, or expose outputs to users in multiple jurisdictions. These patterns can trigger privacy, data protection, contractual, sector, or regulatory obligations.
The enterprise should know where AI Input Data is stored, where it is processed, where model inference occurs, where logs are retained, where outputs are stored, and whether data crosses jurisdictional boundaries.
This information should connect Data and Information records to AI Use Cases, AI Agents, AI Models, Vendors, Locations / Jurisdictions, Regulations, Regulatory Obligations, Controls, and Evidence.
Output Data and Derived Information
AI governance should also consider output data and derived information.
AI outputs may include generated text, summaries, recommendations, classifications, predictions, code, images, audio, decisions, workflow actions, tickets, reports, risk scores, customer messages, employee communications, or system updates. These outputs may become business records, evidence, customer communications, operational instructions, or inputs to downstream processes.
The enterprise should determine which outputs must be reviewed, retained, labeled, disclosed, logged, quality-checked, restricted, or deleted. It should determine whether outputs create new sensitive information or derived data that requires governance.
For example, an AI-generated risk score, employee classification, customer eligibility recommendation, or medical summary may create a governed record even if the original input data was already governed separately.
Relationship to AI Use Cases, Agents, Models, and AI Prompts
Data and Information governance must connect to AI Use Cases, AI Agents, AI Models, and AI Prompts.
An AI Use Case explains why data is being used. An AI Agent explains who or what is using it operationally. An AI Model explains how the data may be processed or interpreted. An AI Prompt explains how the AI is instructed to use the data. The technical asset relationship model explains where the data flows and how controls may be enforced.
These relationships determine whether data use is appropriate. A sensitive data source may be acceptable for one use case and prohibited for another. An AI Prompt may instruct a model to reveal or summarize information that should remain restricted. An agent may have access to a data source beyond what its use case requires. A vendor model may process data in a location that violates residency expectations.
The enterprise must govern these relationships, not only the data source itself.
Governance Questions AI Data and Information Governance Should Answer
For AI Data and Information Governance, governance should answer what exists, who owns it, what is affected, which risks, obligations, controls, evidence, incidents, changes, and gaps require action.
How to cite this page
When referencing this page in academic work, internal standards, or external publications, include the page title, IF4IT as author and publisher (The International Foundation for Information Technology (IF4IT), LLC), the URL, and your access date.
Example (informal web citation):
The International Foundation for Information Technology (IF4IT), LLC. Govern the Data and Information That Feeds AI | Enterprise AI Governance Best Practices. https://if4it.org/best-practices/enterprise-ai-governance-best-practices/govern-the-data-and-information-that-feeds-ai/ (accessed 2026-07-28).
See About Us for content governance and site-wide citation guidance.
Copyright for The International Foundation for Information Technology (IF4IT), LLC: 2008 - Present
Legal Disclaimers