The IF4IT Enterprise Model and Modeling Best Practices - Understand the IF4IT Enterprise Model
The IF4IT Enterprise Model and Modeling Best Practices
Chapter 3. Understand the IF4IT Enterprise Model
Overview
This section is intended to orient the reader to the IF4IT Enterprise Model (IF4IT EM). It defines the model, names its fundamental structural components (e.g., the Taxonomy, the Ontology, and the inventories that realize them), explains why the model is designed for AI consumption, introduces the three load-bearing theses, summarizes the testing evidence, and identifies the audiences and disciplines that shape the document. Subsequent sections expand the structural components, scale concepts, governance practices, adoption path, and operating model.
The combination of these topics is what we refer to as the IF4IT Enterprise Model Semantic Operating Pattern.
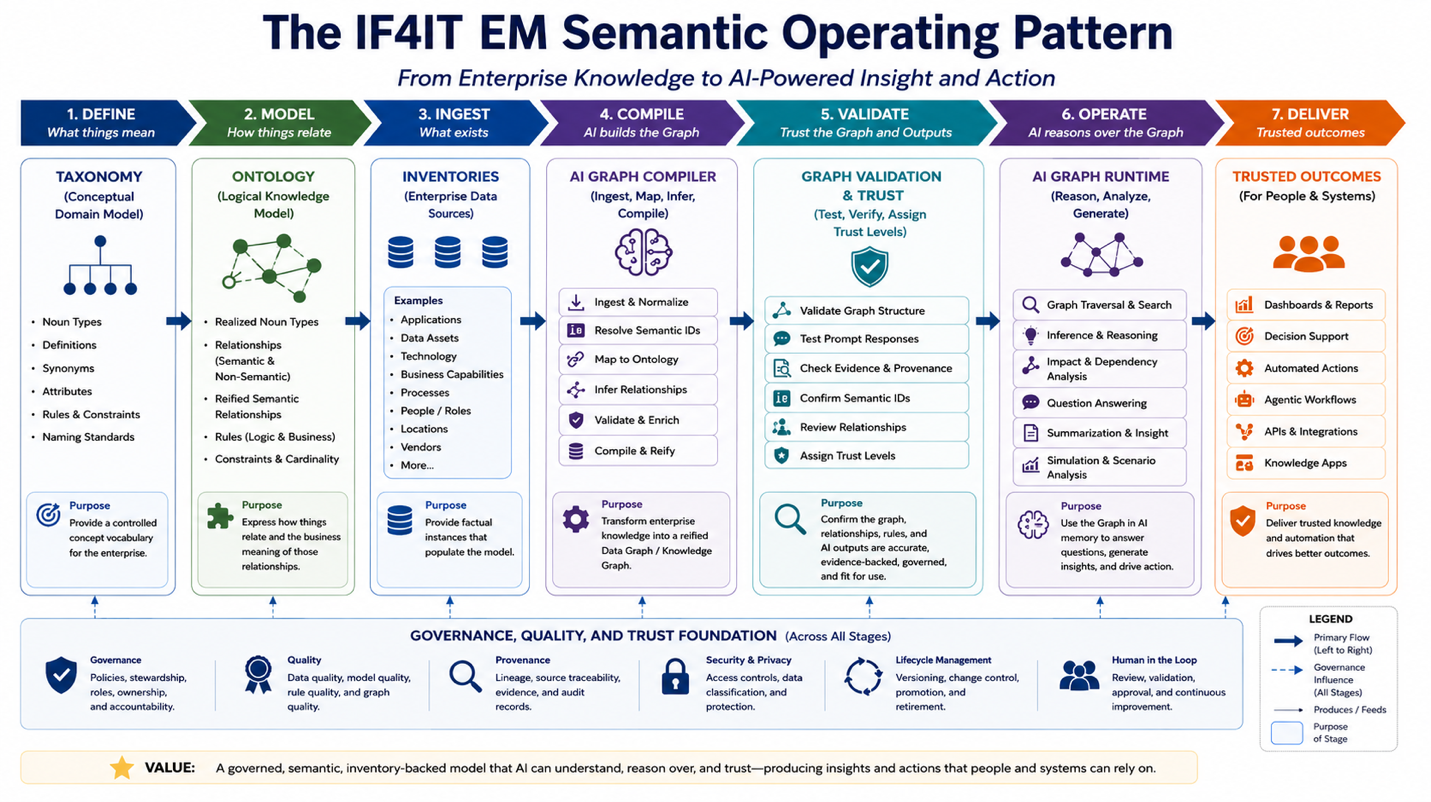
Figure: The IF4IT EM Semantic Operating Pattern – A conceptual architecture for building, validating, and delivering your Enterprise Model.
What the IF4IT Enterprise Model Is
The IF4IT Enterprise Model is the connected representation of an enterprise as a governed, operational, and queryable knowledge graph. It captures what an enterprise has — its applications, capabilities, vendors, contracts, facilities, technologies, business processes, and many more categories of governed assets — and equally importantly, it captures how those things relate, what governs them, and how they combine to produce business outcomes. The IF4IT Enterprise Model is not a database, not a diagram, not the contents of any particular modeling tool, and not a static document. It is a structured body of governed content from which any of those things — and many others — can be produced on demand.
The IF4IT EM is a Semantic Model of the enterprise. It captures what each governed thing is, what it refers to in the real world, and how it relates to other governed things. It does this through a Noun Type Taxonomy, Semantic Identifiers, typed Semantic Relationships, Reified Semantic Relationships, rich attribute content, natural-language rules, and an Ontology that integrates those mechanisms into a coherent definitional and relational substrate. This semantic design is what makes the IF4IT EM natively consumable by AI systems: AI can interpret meaning-bearing source content without first translating everything into a tool-specific schema, a rigid query language, or a single proprietary metamodel.
The model and modeling concepts are scalable. The model can scale in any direction and can represent any domain space, be it a specific industry or even a general topic area.
What AI Consumes and Produces
When this document says the IF4IT EM is natively consumable by AI systems, the claim is practical rather than rhetorical. AI consumes meaning-bearing source content: names, definitions, identifiers, attributes, relationships, rules, and populated inventories. From that content, AI can compile and operate on data and knowledge graphs that support enterprise questions, analyses, visualizations, reports, dashboards, and generated applications.
| AI Consumes Model Components | What It Provides to the Runtime | AI Can Produce |
|---|---|---|
| The Ontology and Taxonomy | Rules for generating the in-memory data graph / knowledge graph. | An in-memory data graph / knowledge graph that can lead to a reified graph. |
| Semantic identifiers | Stable, human-meaningful references to Noun Instances. | Resolved entities, consistent references, and clearer graph nodes. |
| Definitions and natural-language rules | Interpretive context for what things mean, how they should be understood, how they can be structured, and how they can be used. | Rule-aware explanations, validations, and reasoning paths. |
| Attributes and narrative content | Descriptive, predicate, and narrative signals about Noun Instances. | Inferred relationships, summaries, reports, and decision-support outputs. |
| Typed and reified relationships | Meaningful connections among governed things. | Traversals, dependency analysis, impact analysis, and cross-domain answers. |
| Populated inventories | Authoritative records of the enterprise things being governed. | Data and knowledge graphs, dashboards, generated apps, and AI-assisted operating views. |
The distinction of what AI consumes vs. what AI generates matters because most readers come to the topic of enterprise modeling carrying assumptions from earlier eras of the modeling discipline (e.g., highly-typed and structured relational data modeling and structures). The IF4IT EM is not the populated metamodel of a fixed-schema tool. It is not a one-time consulting deliverable presented in a PDF. It is not a wall poster of boxes and arrows. It is a living, governed representation of the enterprise itself, designed to be authored, maintained, evolved, queried, and reasoned over continuously — by humans and by AI as a runtime — at scales that earlier approaches could not reach.
Throughout this document, the IF4IT EM is treated as the subject of substantive intellectual work. The document does not assume the reader has encountered enterprise modeling before; it does not assume the reader has not. It assumes only that the reader is curious about what becomes possible when an enterprise represents itself rigorously, structurally, and in a form that AI can reason over — and what disciplines make that representation worth building.
The Three Structural Components of the Model
The IF4IT EM rests on three pivotal structural components:
the Taxonomy,
the Ontology, and
the Inventories that realize them.
Each is unpacked in detail in future sections of this document; the purpose of naming them here is to establish the structural picture before any of the components is taught deeply.
The Taxonomy is the Catalog of Noun Types the model will contain and that the enterprise governs — the structured listing of the categories of things the enterprise has chosen to inventory. In IF4IT terminology, this is equivalent to the Inventory of Inventories (the term used in the companion IF4IT Enterprise Inventory Management Best Practices document and that rings true with operations and support staff). Traditional data modelers can think of this structure as the Catalog of Data Entities. The Taxonomy can be flat (a simple list) or carry depth (when Noun Types specialize into sub-types). The Taxonomy is a precondition for the rest of the IF4IT EM and is treated in, Understand the Taxonomy, where the concept is introduced, the three-way vocabulary equivalence is named, and the Taxonomy’s relationship to the metamodel concept in Architecture Modeling Tools and to enterprise inventory governance under EIM is addressed. The section, Understand Model Scalability Across Domain Spaces, then develops how the Taxonomy defines the model’s domain space and how the IF4IT EM scales across different enterprise and industry domains, as well as across any topic the reader wishes to model.
The Ontology is the comprehensive definitional and relational substrate that is built on top of the Taxonomy. Where the Taxonomy names the categories of things the enterprise governs and acts as the conceptual model of the domain space, the Ontology realizes and operationalizes those categories. It gives each Noun Type its full identity — what each Noun Type means, its language permutations, what attributes its inventory will carry, how it relates to other Noun Types, what rules govern its interpretation, and how it connects to a homogeneous inventory set of Noun Instances. Readers can think of the Ontology as a set of constructs, definitions, and rules that help generate the live fabric that is the data graph / knowledge graph. The Ontology is where the substantive intellectual work of the IF4IT EM lives; it is what makes the IF4IT EM more than a list of inventories or a diagramming exercise.
The inventories are the populated homogeneous catalogs of Noun Instances — the realized, attribute-bearing records of the actual things the enterprise governs. Each inventory is the realization of exactly one Noun Type defined in the Ontology. Inventories can be physically realized in any accessible form: a flat file, a folder of structured documents, a database query, an API endpoint, a record store such as ServiceNow or Salesforce, a Hugo content directory, a spreadsheet, or any other governed source. The Ontology entry for each Noun Type specifies how and where its realizing inventory is accessed. The IF4IT EM does not impose a storage format on the enterprise; it works with whatever the enterprise already has that can be read by AI agents, wherever the enterprise already has it. The section, Recognize the Inventory as the Realized Population of a Noun Type, treats this third component in detail.
The IF4IT EM also has other constructs, such as but not limited to Semantic Identifiers (IDs), Semantic Relationships, Natural Language Processing Rules, and more. These will be addressed but are considered advanced concepts, as the foundations rest in the above three structures.
These three components together — Taxonomy, Ontology, and inventories — constitute the IF4IT EM at the structural level. They are necessary; they are also not sufficient. What completes the picture, and what makes the IF4IT EM operationally tractable at meaningful enterprise scale, is the role of AI as the runtime that compiles, traverses, visualizes, and reasons over what the three components define.
How Core Concepts Differ
Several IF4IT EM concepts are closely related but not interchangeable. The following table provides a compact orientation before the document develops each concept in more detail.
| Concept | What It Is | What It Is Not | Example |
|---|---|---|---|
| Taxonomy | The catalog of governed Noun Types. | Not the populated inventory records themselves. | Application, Vendor, Contract, Technology, Risk. |
| Ontology | The definitional, attribute, relational, and rules substrate over the Taxonomy. | The definitional, relational, attribute, and rules layer that realizes and operationalizes the conceptual Noun Type Taxonomy. It defines what each Noun Type means, how it relates to other Noun Types, how AI should interpret it, what rules govern it, and how it links to its homogeneous inventory set of instances. In advanced environments, related ontology layers or sub-ontologies may be organized to support multiple domain spaces while preserving practical enterprise-modeling simplicity. | The definition, attributes, relationships, and rules for Application. |
| Inventory | The populated set of Noun Instances for one Noun Type. | Not the Taxonomy; not the Ontology. | The actual list of applications governed by the enterprise. |
| Metamodel | A tool or modeling tradition concept that constrains allowed element and relationship types. | Not the same as the IF4IT EM, though it addresses some similar concerns. | An AMT metamodel defining allowed architecture objects and relationships. |
| Knowledge Graph | A connected representation of instances and relationships. | Not automatically governed or semantically complete by itself. | A graph connecting applications, vendors, contracts, technologies, and risks. |
| Semantic ID | An identifier that has embedded context that is recognizable as part of natural language. | Not a machine legible code (e.g., alphanumeric ID) and not automatically generated. | “Customer Support PostgreSQL Database” or “Doe, Jane (<unique_email_address>)” |
| Semantic Model | A model whose meaning is explicit through names, definitions, relationships, rules, and rich attributes. | Not just a diagram, database, or opaque graph. | The IF4IT EM source content that AI and other runtimes can compile and operate against. |
The Three Load-Bearing Theses for the Enterprise Model
The IF4IT EM and Modeling Best Practices document is organized around three load-bearing theses that are introduced here and developed throughout the document. The theses are sequenced from foundation to practical application — what the IF4IT EM is, how it becomes operational, and what becomes possible when it does.
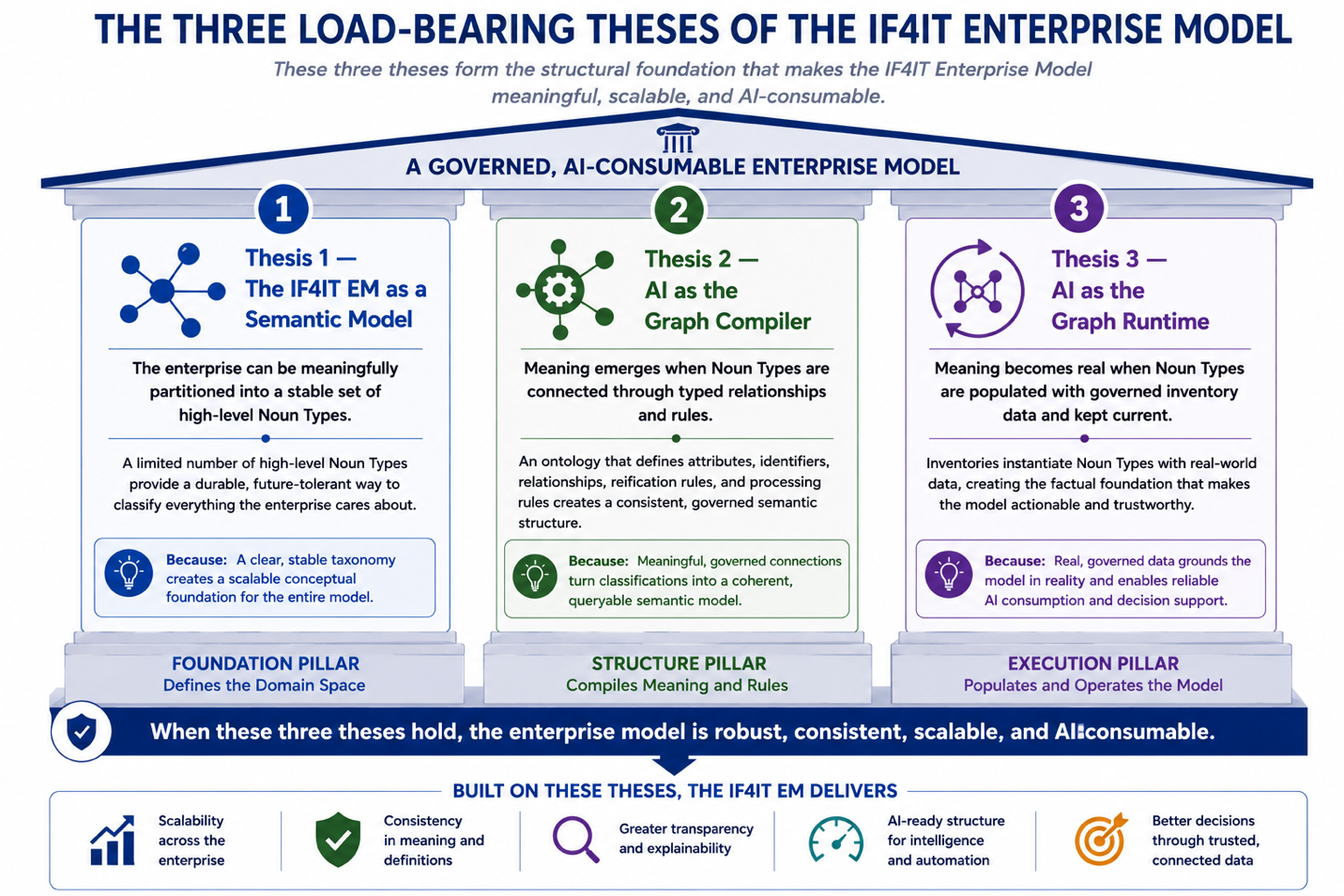
Figure: Conceptual diagram of the three load-bearing theses.
Thesis 1 — The IF4IT EM as a Semantic Model. The IF4IT EM is, by design, a Semantic Model of the enterprise. Its meaning lives at multiple semantic layers — the Taxonomy (the catalog of Noun Types the enterprise governs), semantic identifiers, semantic relationships at the instance level, reified semantic relationships, rich attribute content, and the Ontology that integrates them into a coherent whole — and this design choice is what makes the IF4IT EM natively consumable by AI systems. This thesis is foundational for many reasons but the simplest is that AI operates on Natural Language far more easily and efficiently than it does on traditional unique machine code identifiers. The IF4IT EM exists as a Semantic Model before any tool operates on it.
Thesis 2 — AI as the Graph Compiler. AI reads the model (i.e., the Semantic Model defined in Thesis 1) and compiles (a.k.a. generates or synthesizes) it into data and knowledge graphs. The compilation operates in two distinct modes: in-AI-memory compilation/generation (the graph is assembled in the AI’s working context and is immediately available for operations) and external reified graph compilation/generation (the IF4IT EM’s source artifacts are transformed into formatted output for downstream systems, including Cypher loads for graph databases, RDF for ontology platforms, JSON-LD for web consumers, CSV pairs for spreadsheet tools, and other structures). Both modes have been empirically validated.
Thesis 3 — AI as the Graph Runtime. Once the graph has been compiled, AI operates on it — traversing it, visualizing it, querying it, analyzing it, reasoning over it, producing interactive visualizations, reports, and dashboards from it, and supporting decisions across the enterprise. AI operates in three distinct runtime patterns:
direct in-AI-memory runtime (AI operates on the graph it has compiled into its working context),
direct external runtime (AI operates on graphs stored in downstream systems through query interfaces), and
generated-app runtime (AI produces standalone applications through AI code generation that includes the generated graph). Similar to pattern #2 but slightly different.
All three patterns act as runtime environments over the graph and serve end-users who do not directly engage AI). The third pattern is particularly significant because it allows the IF4IT EM’s value to reach enterprise audiences without requiring AI literacy or AI access per user. Future sections help better understand AI as the Graph Runtime to better develop this thesis.
Summary of the Three Load-Bearing Theses
The three theses are sequenced — Model, then Compile, then Operate — and each builds on the one before. A reader who understands all three has the full intellectual architecture the IF4IT EM and Modeling Best Practices document develops. A reader who needs only one or two for their immediate purposes can read those sections without losing the coherence of what they get.
The following summary provides an at-a-glance view of how the three theses relate to one another. The rest of the document expands each thesis and the disciplines required to make it operational.
| Thesis | Core Claim | Primary Input | Primary Output | Runtime Role | Evidence |
|---|---|---|---|---|---|
| Thesis 1 - The IF4IT EM as a Semantic Model | The IF4IT EM is a governed semantic representation of the enterprise constructs and data. | Taxonomy, Ontology, semantic identifiers, relationships, rich attributes, and inventories. | A complete operational specification of enterprise meaning. | Defines the model AI and other runtimes operate against. | Validated structurally through tool ingestion and utilization (e.g., IF4IT NOUNZ and various AI offerings). |
| Thesis 2 - AI as the Graph Compiler | AI can read the IF4IT EM and compile it into data and knowledge graphs. | IF4IT EM source artifacts and populated inventories. | In-AI-memory graphs or external graph outputs. | Transforms semantic source content into operational graph structures. | Validated through AI pilots and external graph generation. |
| Thesis 3 - AI as the Graph Runtime | AI can operate on compiled graphs to deliver enterprise value. | Compiled in-memory or external graphs. | Answers, traversals, analyses, visualizations, reports, dashboards, and generated apps. | Acts as the active operator over the graph. | Validated through direct AI runtime, external runtime, and generated-app runtime patterns. |
How the IF4IT EM Has Been Validated
The concepts in this document are not aspirational. They have been validated through empirical testing across both non-AI and AI runtimes, with the validation mapping cleanly to the three load-bearing theses (described earlier).
Two different toolsets were used to validate the IF4IT EM:
IF4IT NOUNZ Data Compiler (not needed by the reader of this document), and
Various AI agent offerings that include comprehensive generative and reasoning features.
The non-AI validation has been carried out through IF4IT NOUNZ (not needed by the reader), a custom data compiler the IF4IT has built that fully implements the bulk of IF4IT EM concepts that are not AI-related — the Taxonomy, the Ontology, Noun Types, attributes, inventories, and rules — and that synthesizes data and knowledge graphs (including reified semantic relationships), catalogs, visualizations, data traversals, and dashboards from the IF4IT EM’s source artifacts. NOUNZ is a deterministic compiler; it does not rely on AI’s general reasoning capabilities. That it successfully, repeatedly, and consistently produces the expected outputs is a mechanical proof that the IF4IT EM concepts constitute a complete operational specification. NOUNZ has also been validated for external graph generation — producing formatted output that can be loaded into downstream systems — and for the corresponding external-runtime patterns that operate on those outputs.
The AI validation has been carried out through multiple enterprise pilots run across three separate, publicly available, paid-for AI agents offering significant generative capabilities that natively allowed for things like in-AI-memory graph generation, graph traversal, graph interpretation, graph visualizations, and more. (If you’re wondering, all major AI offerings do most of these things.)
The tests with the above mentioned tools covered distinct subject matters including healthcare payers, large and small life-sciences and pharmaceutical companies, an energy company, and additional enterprise models. Each AI agent successfully ingested and operated against each of these models. The pilots produced answers, reports, visualizations, and interactive dashboards across the full set of subject matters. The Healthcare Payer pilot is referenced throughout this document as one specific concrete example, but the empirical scope is broader: the validation has been demonstrated as a property of the IF4IT EM approach across multiple distinct subject matters, not a coincidence of fit between a single test model and the AI agents’ training. The result is significant because none of the three AI agents shares an internal implementation schema with the others, yet each operated against the IF4IT EM successfully — demonstrating implementation-schema-independence in practice. And, while each was able to handle structural tests similarly, it was very interesting to see the different insights each different agent fashioned from working with the same semantic model.
Together, NOUNZ and the multi-pilot AI testing establish three things: that the IF4IT EM is structurally complete (Thesis 1 — a deterministic compiler can execute the Semantic Model as a complete operational specification), that both compilation modes of Thesis 2 work in practice (in-AI-memory compilation across all three AI agents, and external graph generation through both NOUNZ and the AI agents), and that all three runtime patterns of Thesis 3 work in practice (direct in-AI-memory runtime through the AI pilots, direct external runtime when generated outputs are loaded into downstream tools, and generated-app runtime through AI code generation of standalone applications). The dual evidence — a purpose-built non-AI compiler plus three general-purpose AI agents operating across multiple tests — provides a stronger decoupling argument than either kind of testing alone would deliver.
Who This Document Is For
The IF4IT EM document is written for two audiences with overlapping but distinct needs.
IT and Business Leadership readers — executives, sponsors, and decision-makers responsible for enterprise self-knowledge and the investments that produce it — need to understand the value of building, having, and leveraging the IF4IT EM within their own enterprise. They need guidance on getting it started in their enterprises, giving it ownership, and securing the executive sponsorship its success requires. They need to understand the strategic position the discipline produces and the durable enterprise asset it represents.
Practitioner readers — enterprise architects, data architects, modeling practitioners, governance leads, and the working-level professionals who will actually build and maintain the IF4IT EM — need substantive guidance on how to build, expose, and govern it. They need the conceptual depth that makes the discipline coherent and the practical workflow that makes it executable. They need to know when to reify a relationship, when to specialize a Noun Type, how to author rich attribute content, and how to work with AI as both the Graph Compiler and the Graph Runtime.
Both audiences are served by a single document rather than by two separate documents. This is by deliberate choice. The leadership case for the IF4IT EM is strengthened by visibility into the practitioner depth that backs it; the practitioner case is strengthened by visibility into the strategic position the discipline produces. A document that addressed only one audience would lose what the other audience contributes to the credibility of the whole.
Disciplines This Document Follows
Several disciplines govern how the IF4IT EM document is written and how its claims are presented. These disciplines are worth naming explicitly so that readers can recognize them in operation.
Specification-adjacent precision over manifesto register. The IF4IT EM document makes assertions — about what the IF4IT EM is, about what AI as the Graph Compiler and the Graph Runtime makes possible, about how the discipline differs from earlier approaches. Such claims can only be credible when they are concrete, illustrated, and careful about what they require and what they leave open. As discussed above, the IF4IT has internally validated its claims using two tools: 1) its custom built NOUNZ data compiler that builds data/knowledge graphs and synthesizes a surrounding graph runtime environment, and 2) AI, which includes multiple different AI agent platforms that were able ingest the model, synthesize an internal graph data/knowledge structure, and work with it in many different ways. In this manner, the document earns its claims through precision rather than through volume.
References to third-parties and third party artifacts. The IF4IT EM document occasionally references other organizations, frameworks, and product categories throughout. The IF4IT goal is not to criticize such entities but to leverage established solutions as examples for intellectual baselines and comparisons. The intellectual goal is to offer concepts that cause readers to think, assess, and reach their own conclusions on the merits. Some of those entities might, in fact, adopt the IF4IT EM for their own use.
Calibrated citation of empirical results. When the IF4IT EM document cites IF4IT empirical results — NOUNZ, the AI-runtime research, or others — those citations are calibrated to what has actually been tested. The results referenced what worked, what required iteration, and what limitations were observed are reported honestly. Unqualified success language is avoided.
Living-document framing. The IF4IT EM document is designed to evolve. It publishes what is known now, with the explicit intention of returning to enhance and grow each section as IF4IT’s understanding deepens. Readers should expect later versions to extend rather than replace what they read here. The structure of the document is built to accommodate this — each section is self-contained enough that future additions slot into the existing structure rather than requiring restructuring. The Table of Contents at the front of the document shows the full intended structure; the current edition includes a subset of those sections, with the remainder to be added in subsequent editions.
How to Read This Document
Readers may read the document sequentially or move to the sections most relevant to their immediate needs. Each section is self-contained enough to be read on its own when a reader arrives at it from a search engine or from a cross-reference. The first mention of the IF4IT EM in every section spells out the full name; subsequent mentions within the same section use the abbreviated form (the IF4IT EM). This convention is followed throughout the document and across all IF4IT articles and ancillary documents that reference the IF4IT EM.
Copyright for the International Foundation for Information Technology (IF4IT): 2008 - Present
Legal Disclaimers