The IF4IT Enterprise Model and Modeling Best Practices - Use AI as the Graph Compiler and Runtime
The IF4IT Enterprise Model and Modeling Best Practices
Chapter 8. Use AI as the Graph Compiler and Runtime
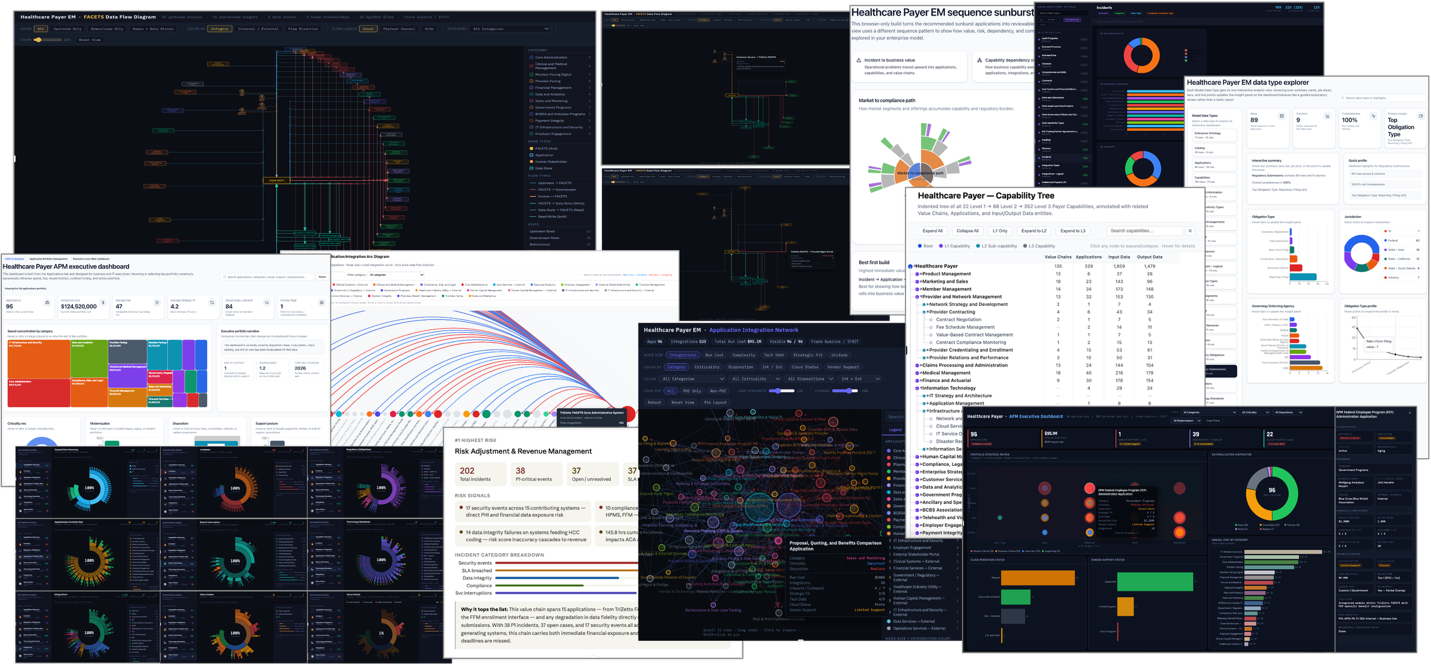
Figure: Examples of on-demand, AI-synthesized, visual, and interactive knowledge constructs from Enterprise Models.
Overview
The IF4IT Enterprise Model becomes operational when AI can ingest, compile, deliver, and operate against it. The Taxonomy, Ontology, Inventories, Semantic Identifiers, attributes, relationships, rules, and governance guidance are the source content. AI acts on that source content by compiling it into a working Data Graph / Knowledge Graph and then operating against that graph as a runtime environment.
This section explains two connected but distinct concepts:
| Concept | Meaning |
|---|---|
| AI as the Graph Compiler (a.k.a. “Graph Synthesizer” or “Graph Generator”) | AI ingests the IF4IT EM constructs and compiles them into a working graph representation. |
| AI as the Graph Runtime | AI operates against the compiled graph to support model improvement, stakeholder use, analysis, reporting, visualization, decision support, and generated outputs. |
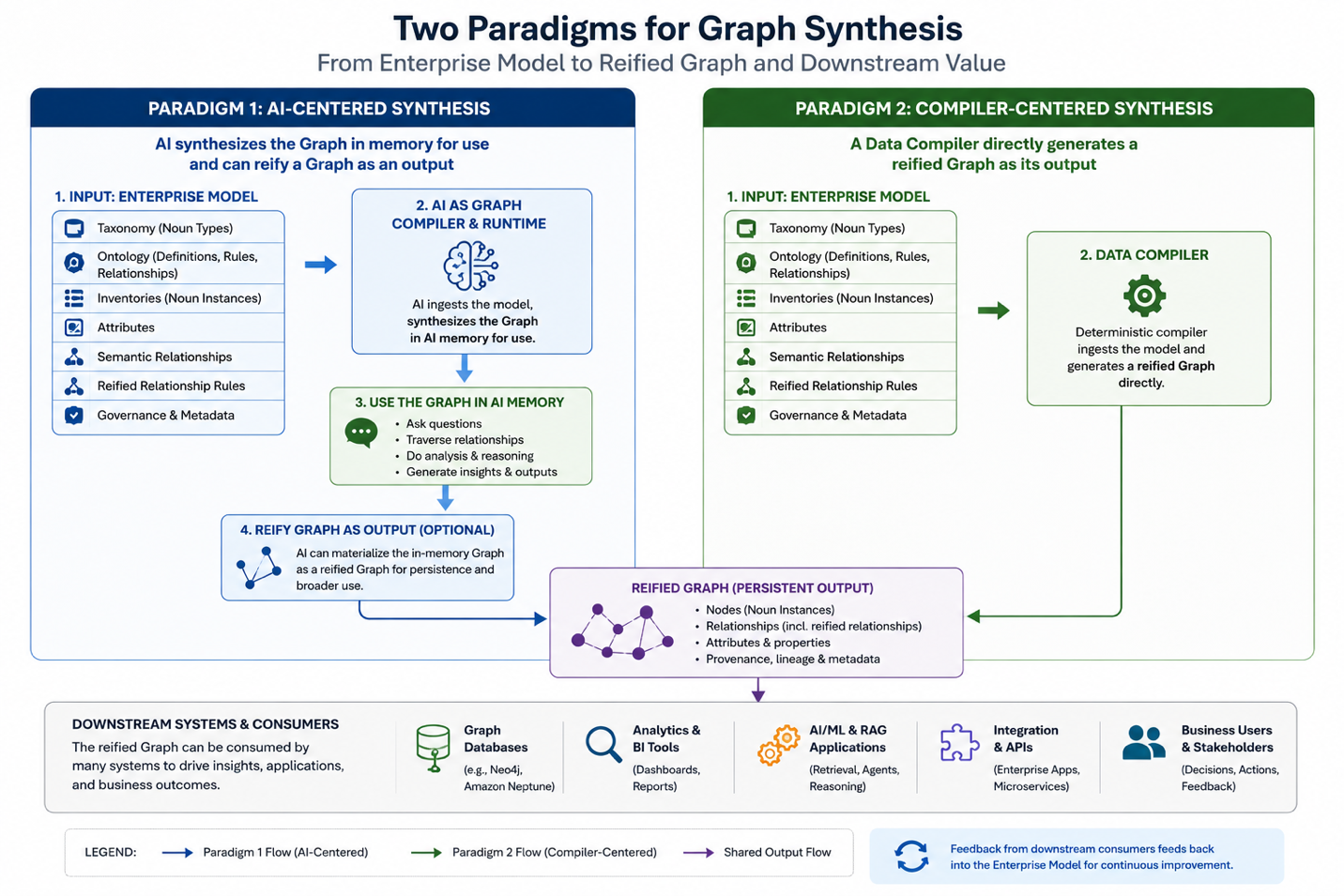
Figure: Two distinct Graph Synthesis (a.k.a. Graph Compilation) paradigms for Enterprise Model generation.
The distinction matters…
Compilation makes the IF4IT EM usable by AI.
Runtime utilization makes the IF4IT EM valuable to people.
The IF4IT EM can be used in two complementary operating permutations. In the first, a modeler loads or connects the IF4IT EM source artifacts into a private AI session, where AI compiles/synthesizes/generate an in-AI-memory Data Graph / Knowledge Graph that the modeler can inspect, test, improve, and govern. In the second, the IF4IT EM is packaged into a Shared Enterprise AI Runtime so many authorized stakeholders can use a common governed model for day-to-day business analysis, decision support, governance, and operational work.
The private modeler workspace improves the model and acts as a private development and testing environment. The Shared Enterprise AI Runtime delivers the model. Both depend on the same governed semantic foundation.
AI compiles the IF4IT EM into a working graph
AI can ingest the IF4IT EM’s source constructs and compile (a.k.a. “synthesize” or “generate”) them into a working Data Graph / Knowledge Graph. This compilation process is not limited to reading tables or summarizing documents. AI consumes the meaning-bearing components of the IF4IT EM and assembles them into a connected graph representation (in its own brain memory) that can be traversed, queried, analyzed, visualized, compared, improved, and reasoned over.
The model constructs AI may ingest include:
| IF4IT EM Construct | What AI Uses It For |
|---|---|
| Taxonomy | Understands the Noun Types recognized by the model and the domain space being modeled. |
| Ontology | Understands definitions, language, attributes, relationships, rules, governance, and interpretation guidance. |
| Inventories | Finds the real-world Noun Instances that populate the model. |
| Semantic Identifiers | Resolves and references Noun Instances consistently across sources. |
| Attributes | Interprets descriptive, predicate, narrative, operational, and governance context. |
| Semantic Relationships | Connects Noun Instances across inventories and domains. |
| Reified Semantic Relationships | Treats important relationships as first-class semantic constructs with their own attributes, evidence, confidence, provenance, governance, and lifecycle. |
| Natural-language rules | Guides AI interpretation, mapping, inference, validation, cleanup, reification, and output generation. |
| Source metadata and provenance | Helps AI understand where facts, records, relationships, and suggestions came from. |
| Governance guidance | Helps AI distinguish candidate knowledge from reviewed, trusted, or promoted model truth. |
The graph that AI compiles is a runtime expression of the IF4IT EM. It is not a replacement for the governed source model. The source model remains the durable, maintainable body of governed enterprise content. The compiled graph is the working structure AI can use to answer questions, generate outputs, inspect gaps, find relationships, support decisions, and recommend improvements.
To further depict this, consider that changing one single descriptive attribute, such as the Description attribute for an Application. Doing so can significantly alter the generated in-AI-memory data graph enough to change working outcomes because relationships between nodes might change.
Compilation can be in-memory or externally reified
AI compilation can occur in two primary modes: in-AI-memory compilation and external graph generation.
| Compilation Mode | Description | Typical Use |
|---|---|---|
| In-AI-memory compilation | AI ingests the IF4IT EM source artifacts and assembles a working graph inside its own session, context, or runtime environment. | Fast exploration, modeler analysis, stakeholder questions, pilot use, model inspection, graph reasoning, and short-cycle improvement. |
| External graph generation | AI or deterministic tooling compiles/ generates/synthesizes graph-compatible output that can be stored, loaded, queried, versioned, visualized, or used by downstream systems. | Persistent runtimes, graph databases, ontology platforms, document stores, generated applications, dashboards, auditability, and shared enterprise delivery. |
In-AI-memory compilation is powerful because it allows AI to work with the model immediately. The modeler can provide the IF4IT EM source artifacts, allow AI to compile a working graph, and then ask AI to inspect the graph, traverse it, explain it, compare portions of it, generate interactive visualizations, or identify improvement opportunities.
External graph generation is powerful because it allows the compiled graph to persist outside a single AI session. A reified graph can be loaded into downstream systems, versioned, queried, secured, visualized, backed up, restored, or used by applications. External graph generation can be performed by AI, by deterministic tooling, or by a hybrid pattern that uses AI and deterministic software together.
The important distinction is this:
The IF4IT EM is the governed source model that is decoupled not just from the synthesized graph but also from the tool. The graph is a generated expression of that model. The graph can live temporarily in AI memory, or it can be externally reified for persistence and broader runtime use. The point is that if you control and snapshot the model, you can always resynthesize the graph from it.
Use Snapshots to Preserve, Restore, and Compare Model States
As the IF4IT Enterprise Model matures, the enterprise should treat snapshots as an important model-management concept. A snapshot is a point-in-time capture of an input model state, graph state, source state, output state, or runtime state. Snapshots allow the enterprise to preserve what existed at a specific moment, restore a prior known-good state, compare one model state to another, support auditability, and enable model parallelism.
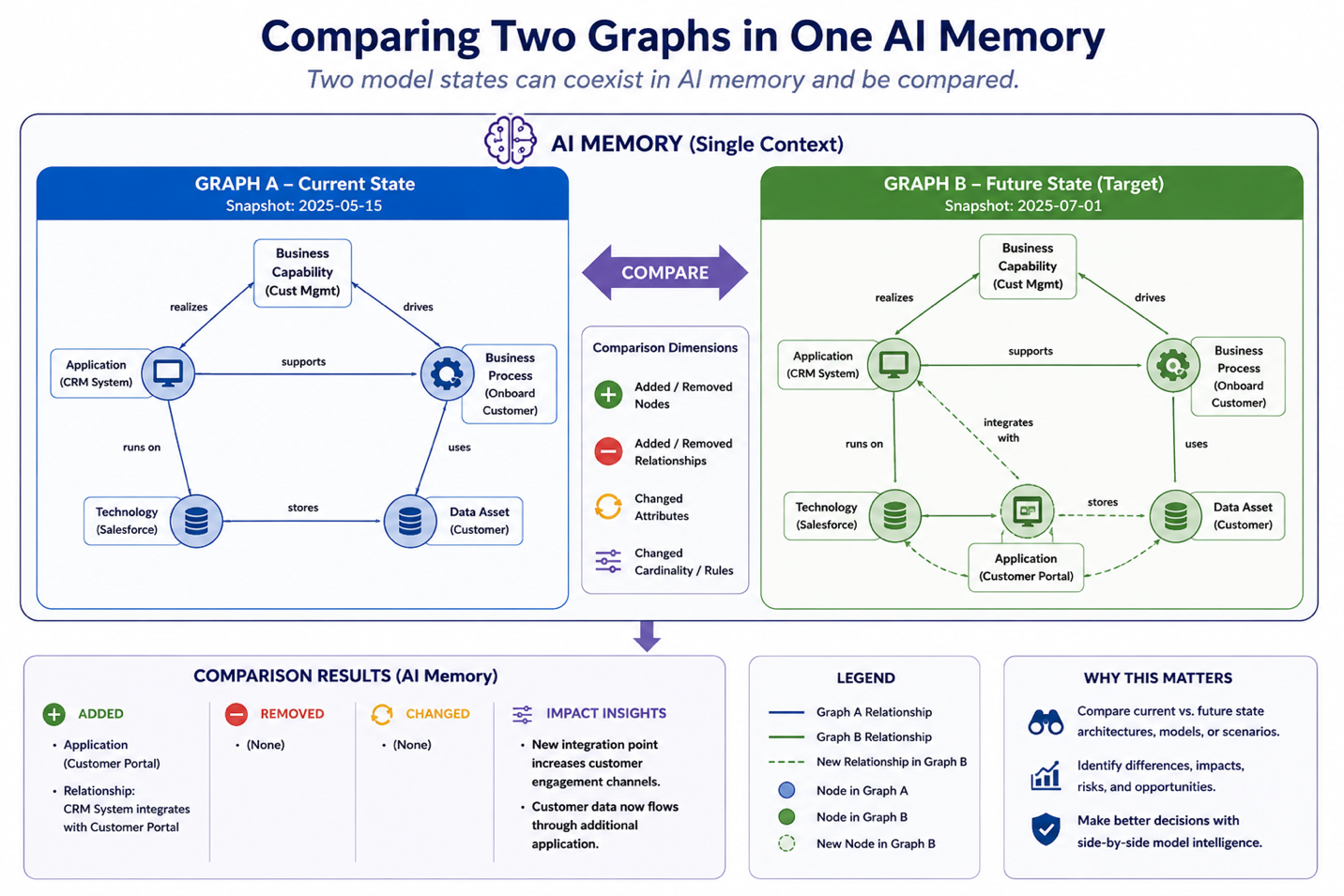
Figure: Comparing two graphs in one AI memory allows simplified detection of differences.
A backup is one use of a snapshot, but not every snapshot is only a backup. In the IF4IT EM, snapshots are broader than recovery copies. They can preserve model inputs, generated graph outputs, reified graph structures, prompt / response baselines, dashboards, reports, or other outputs that help the enterprise understand how the model existed and behaved at a particular point in time.
| Concept | Meaning | Relationship |
|---|---|---|
| Snapshot | A point-in-time capture of a model state, graph state, source state, output state, or runtime state. | The broader concept. Enables backup, restore, comparison, audit, rollback, validation, and model parallelism. |
| Backup | A preserved snapshot intended for recovery or restoration. | A recovery-oriented use of a snapshot. |
| Restore / Recovery | The act of reinstating a prior known-good model, graph, or output state. | Depends on preserved snapshots or backups. |
| Comparison | The analysis of differences between two or more snapshots. | Depends on captured states that can be compared. |
| Model Parallelism | The ability to hold or reason over multiple model or graph states at the same time. | Often depends on snapshots, versions, or generated graph states. |
Snapshots are especially important because the IF4IT EM can exist in several related forms. The governed source model may include Taxonomy, Ontology, Inventories, rules, attributes, Semantic IDs, relationship definitions, reification guidance, and governance metadata. AI or deterministic tooling may then compile those inputs into in-AI-memory graphs, externally reified graphs, dashboards, reports, visualizations, generated applications, or other runtime outputs. Each form may need to be captured for different reasons.
| Snapshot Type | What It Captures | Why It Matters |
|---|---|---|
| Model input snapshot | Taxonomy, Ontology, Inventories, rules, prompts, mappings, Semantic ID guidance, relationship rules, and governance metadata. | Preserves the source content used to compile or generate a model state. |
| Inventory snapshot | The source inventory records available at a specific point in time. | Supports audit, source comparison, data-quality review, and recovery from bad source changes. |
| Ontology / rule snapshot | Noun Type definitions, attributes, relationship rules, reification rules, inventory-processing rules, and AI guidance. | Allows rule changes to be tested, compared, rolled back, and audited. |
| In-AI-memory graph snapshot | A captured description or export of a graph that AI compiled in memory. | Helps preserve useful exploratory graph states that would otherwise disappear after the AI session. |
| Reified graph snapshot | An externally generated graph output, such as a graph database load file, RDF, JSON-LD, GraphML, CSV edge list, or similar graph-compatible artifact. | Provides a persistent graph state that can be stored, restored, loaded, queried, compared, or reused. |
| Runtime output snapshot | Dashboards, reports, generated applications, visualizations, model-health outputs, or decision-support artifacts. | Preserves what users saw or used at a specific point in time. |
| Prompt / response snapshot | Known prompts, expected responses, actual responses, evidence paths, and validation results. | Supports UAT, regression testing, and runtime behavior validation. |
Snapshots help avoid a common problem: treating generated runtime outputs as if they are durable merely because they appeared useful during a session or demonstration. An in-AI-memory graph may be valuable, but it is temporary unless the modeler captures enough of it to reproduce, compare, reify, or validate it later. Similarly, a dashboard, report, or graph traversal may be useful, but the enterprise may need to know which source model, inventory version, rules, and graph state produced it.
The IF4IT EM should distinguish between source preservation and output preservation.
| Preservation Focus | Description | Example |
|---|---|---|
| Preserve the source model | Capture the inputs needed to regenerate the graph or outputs later. | Snapshot the Taxonomy, Ontology, Inventories, rules, and mappings used for a release. |
| Preserve the generated graph | Capture the graph expression produced from the source model. | Store a reified graph output that can be loaded into a graph database. |
| Preserve the runtime output | Capture what users or testers consumed. | Preserve a dashboard, report, visualization, prompt response, or impact-analysis result. |
| Preserve the validation baseline | Capture expected behavior for future testing. | Store UAT prompt / response baselines and expected graph traversal paths. |
Backups should be understood as preserved snapshots used for recovery. A backup may preserve a known-good version of the source model, a reified graph output, or a runtime delivery package. If a bad rule change, bad inventory update, failed ingestion, poor AI inference, or defective runtime configuration damages the model or produces unreliable outputs, a backup snapshot allows the enterprise to restore a prior known-good state.
| Backup Use Case | Description |
|---|---|
| Source model recovery | Restore a prior version of Taxonomy, Ontology, Inventories, rules, prompts, mappings, or governance metadata. |
| Reified graph recovery | Reload a prior generated graph into a downstream graph database, ontology platform, document store, or runtime. |
| Runtime recovery | Restore a prior dashboard, generated application, report package, agent configuration, or runtime behavior baseline. |
| UAT recovery | Return to a prior validated test baseline when new changes introduce regressions. |
| Production rollback | Revert a production Shared Enterprise AI Runtime to a known-good model state or graph state. |
Snapshots also make comparison possible. A modeler can compare one snapshot to another to identify changes, drift, regressions, improvements, or unintended consequences. This is important because the IF4IT EM is expected to evolve. Inventories change. Ontology rules improve. Noun Types are added or retired. Relationships are inferred, reviewed, reified, approved, or rejected. Runtime outputs mature. Without snapshots, the enterprise may not know what changed, when it changed, or why results are different.
| Comparison Type | Example Question |
|---|---|
| Past vs. present | What changed in the model since the last approved release? |
| Current vs. future | How does the current enterprise model compare to the intended target-state model? |
| Before vs. after rule change | Which relationships, Semantic IDs, or outputs changed after the Ontology rule update? |
| Before vs. after inventory refresh | What changed after the latest inventory ingestion? |
| UAT baseline vs. current output | Did AI responses, graph traversals, dashboards, or reports regress after the latest changes? |
| Scenario A vs. Scenario B | Which proposed future-state model produces fewer risks, dependencies, conflicts, or gaps? |
Snapshots are also useful for audit and governance. They help explain what model content was in effect at the time an AI-generated output, dashboard, recommendation, or decision-support artifact was produced. They also help answer questions about provenance, evidence, trust level, approval status, and production readiness.
| Governance Need | How Snapshots Help |
|---|---|
| Auditability | Preserve what the model contained when an output was generated. |
| Evidence | Retain source records, graph paths, rules, prompts, and outputs used to support a conclusion. |
| Trust levels | Show whether output was unassessed, exploratory, candidate, evidence-backed, reviewed, or approved at the time. |
| Promotion control | Preserve DEV, UAT, and PROD model states as changes move through environments. |
| Regression detection | Compare current outputs to prior expected outputs. |
| Accountability | Identify which source inventories, rules, or model changes contributed to a runtime result. |
Many traditional Architecture Modeling Tools struggle with these concerns because they often treat the model as a live repository rather than a set of reproducible source inputs and generated runtime expressions. They may provide exports, copies, or repository backups, but they often make it difficult to capture, restore, compare, and operate on multiple full model states in a flexible way. The IF4IT EM should preserve the stronger pattern: model inputs are governed source content, graphs are generated expressions, and snapshots allow both to be preserved, restored, compared, and reused.
For early implementations, snapshots do not need to be complex. A snapshot may begin as a dated folder of all inputs, a repository branch, a tagged release, an exported graph file, a saved prompt / response test pack, or a versioned model package. As the IF4IT EM matures, snapshots may become more formal through version-controlled repositories, automated graph exports, environment-specific releases, model-release notes, test baselines, backup schedules, and production rollback procedures.
| Maturity Level | Snapshot Practice |
|---|---|
| Early | Save dated copies of source artifacts, inventory extracts, prompts, and generated outputs. |
| Controlled | Use versioned folders, repository tags, release notes, and manual restore points. |
| Managed | Maintain DEV, UAT, and PROD snapshots with validation baselines and rollback procedures. |
| Advanced | Automate snapshot creation, graph export, test comparison, release promotion, and recovery workflows. |
The practical principle is simple:
Capture the model state before important changes. Preserve known-good states. Use snapshots for recovery, comparison, audit, validation, and parallel analysis. Treat backups as recovery-oriented snapshots, not as the full extent of snapshot value.
Private Modeler Workspaces and Shared Enterprise AI Runtimes serve different purposes
The IF4IT EM can operate through two complementary permutations: a private modeler workspace, commonly referred to as the Development Environment, and a Shared Enterprise AI Runtime, commonly referred to as the Production Environment.
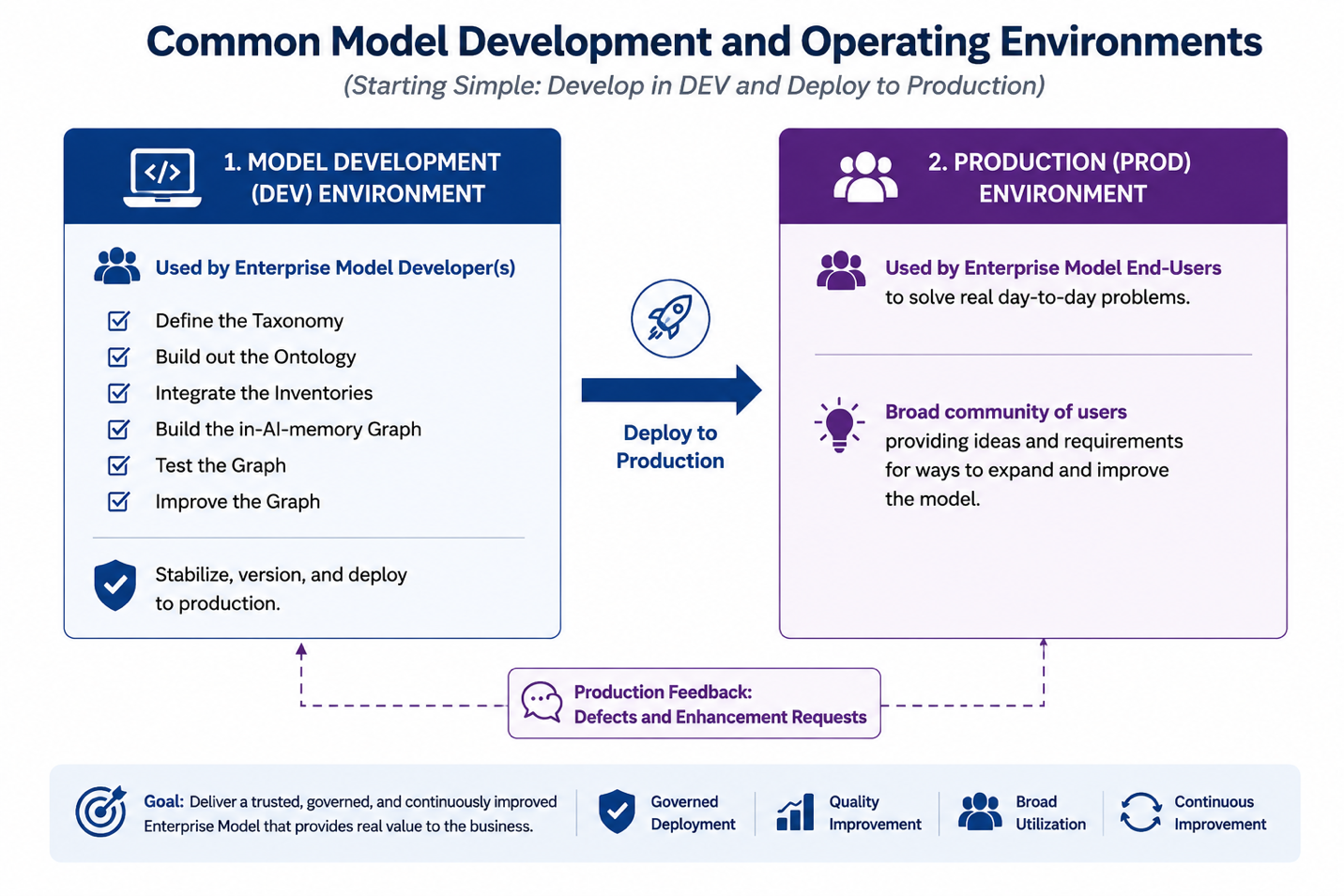
Figure: A common ‘starter’ two-environment delivery pipeline.
In the private modeler workspace permutation (also known as Development), the modeler uses AI as a working partner. The modeler loads or connects the IF4IT EM source artifacts into a private AI session. AI compiles an in-AI-memory graph and helps the modeler inspect, test, improve, and govern the model. This pattern is especially useful while the model is being authored, expanded, corrected, validated, or prepared for broader use.
In the Shared Enterprise AI Runtime permutation, the IF4IT EM is packaged for broader consumption (e.g., Production). The model is delivered through a governed runtime pattern so multiple authorized users can work against a common model for day-to-day business analysis, operational support, governance activities, and decision-making.
| Dimension | Private Modeler Workspace | Shared Enterprise AI Runtime |
|---|---|---|
| Primary purpose | Build, inspect, test, improve, and govern the model. | Deliver model value to broader enterprise stakeholders. |
| Primary users | Modelers, architects, Ontology Stewards, Inventory Owners, governance leads. | Executives, business stakeholders, architects, analysts, risk teams, operations teams, product teams, finance teams, technology teams. |
| Graph posture | Usually compiled in AI memory for immediate modeler use. | May be delivered through custom agents, AI RAG, Graph-RAG, Agentic RAG, external graph runtimes, generated applications, dashboards, reports, or hybrid delivery patterns. |
| Typical activities | Find gaps, test rules, improve attributes, generate Semantic IDs, identify weak inventories, infer relationships, validate mappings. | Ask questions, perform impact analysis, explore dependencies, consume dashboards, analyze risks, generate reports, support decisions. |
| Output posture | Experimental, candidate, exploratory, and subject to review. | More governed, role-aware, reusable, explainable, and fit for business consumption. |
| Governance emphasis | Human-in-the-loop review, modeler validation, evidence checks, source inspection. | Access control, provenance, refresh discipline, usage governance, stakeholder trust, output quality. |
| Maturity posture | Strong Crawl or early Walk pattern. | Strong Walk or Run pattern for enterprise-scale adoption. |
The two permutations (Development and Production) should reinforce each other. A private modeler workspace can generate improvement candidates that feed the governed source model. A Shared Enterprise AI Runtime can expose the governed model to users. Stakeholder use can create feedback that becomes new model-improvement input for modelers, Inventory Owners, and Ontology Stewards.
The resulting cycle is simple:
Private workspace improves the model. Shared runtime delivers the model. Shared use produces feedback. Feedback improves the model.
Consider a Three-Environment Pipeline for Higher Quality
As the IF4IT Enterprise Model matures from a private modeling artifact into a shared enterprise capability, consider that testing of the model becomes as important as testing of a complex software application; especially when considering that work decisions will be made based on the quality of the model data. For this reason, it is suggested that you consider a three-environment pipeline for model development, testing, and delivery. In a two-environment pipeline, the model is developed in the Development environment and is directly deployed to the Production environment for immediate and broader utilization by end-users (just alike a software application). However, as the model grows, the ability to test all aspects of the model becomes a significant task by itself. This may warrant dedicated testers and dedicated automated testing tools that need to exercise a stable version of the model that is neither in Development nor in Production. An example of such an environment is one that is commonly called User Acceptance Testing (UAT).
Using this three-environment delivery pipeline mirrors the familiar software development lifecycle pattern of having your model evolve in Development, move into a User Acceptance Testing environment where it can be better and more thoroughly tested by SMEs and automation, and finally be deployed to a Production working environment where users can work with a high-confidence model.
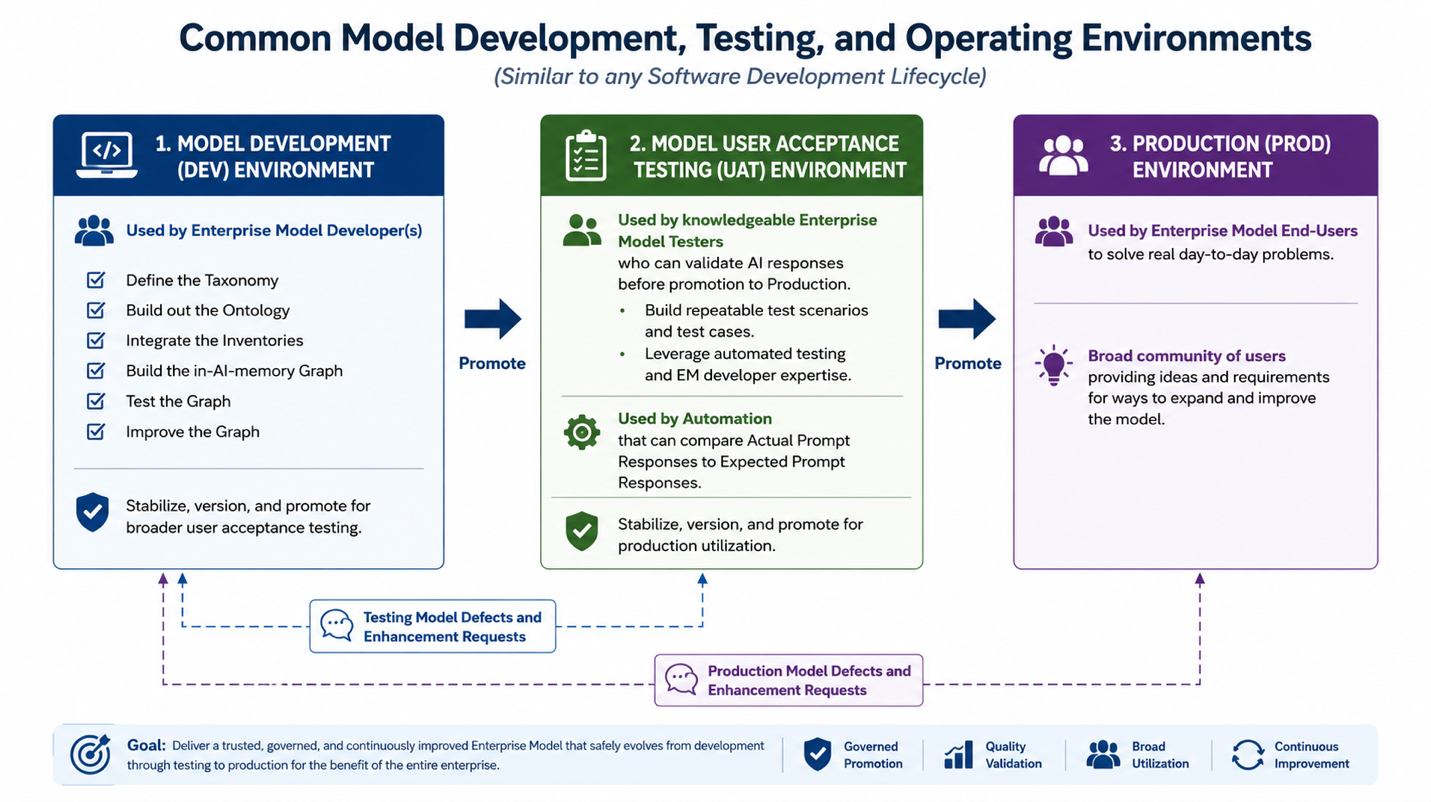
Figure: Example of a three-environment model delivery pipeline.
The goal is not to make model governance unnecessarily heavy. The goal is to separate experimentation from trusted use, validate AI behavior before broad exposure, and give the enterprise a safe path for promoting model changes into broader stakeholder-facing runtime environments.
A simple three-environment pipeline pattern is a way to ensure testing teams can work in isolation to better ensure model quality before delivery.
| Environment | Purpose | Primary Users | Typical Activities |
|---|---|---|---|
| Model Development (DEV) | Build, inspect, test, and improve the IF4IT EM before broader validation. | Modelers, architects, Ontology Stewards, selected Inventory Owners, governance leads. | Define the Taxonomy, evolve the Ontology, integrate Inventories, compile working graph expressions, test rules, infer relationships, generate Semantic IDs, inspect graph quality, and stabilize candidate changes. |
| Model User Acceptance Testing (UAT) | Validate model behavior, AI responses, graph outputs, dashboards, reports, and use cases before promotion to production use. | Controlled testers, subject-matter experts, Inventory Owners, governance leads, automation owners. | Run repeatable test scenarios, validate AI responses, compare actual outputs to expected outputs, test prompt / response behavior, validate impact analysis, review relationship inference, verify dashboards, and confirm stakeholder readiness. |
| Production (PROD) | Deliver governed model capabilities to the broadest authorized stakeholder audience. | End-user stakeholders, executives, analysts, architects, risk teams, operations teams, product teams, technology teams. | Ask questions, perform impact analysis, explore dependencies, consume dashboards and reports, support decisions, submit feedback, and identify production defects or enhancement requests. |
This environment model is especially important when AI is used as both Graph Compiler and Runtime. In DEV, a modeler may compile and test an in-AI-memory graph privately but the modeler will never have the capacity to test all aspects of the model. In UAT, controlled testers may validate significantly more repeatable prompts, expected answers, graph traversals, relationship paths, generated dashboards, model-health outputs, and stakeholder-facing use cases. In PROD, authorized users may then work against a governed Shared Enterprise AI Runtime that exposes the approved model through agents, RAG, Agentic RAG, Graph-RAG, external graph runtimes, generated applications, dashboards, reports, or hybrid runtime patterns.
As mentioned, UAT can include both manual and automated validation. Manual testers can evaluate whether AI responses are useful, accurate, explainable, role-appropriate, and fit for stakeholder use. Automated tests can compare actual prompt responses to expected prompt responses, confirm that known relationships are returned, verify that known impact-analysis paths are traversed, check that expected evidence or provenance appears, and detect regressions when inventories, ontology rules, prompts, model content, or runtime behavior change.
| Testing Focus | Example Validation Question |
|---|---|
| Prompt / response quality | Does the AI answer the question using the expected model content and evidence? |
| Relationship traversal | Does the AI find the expected upstream, downstream, or cross-domain relationships? |
| Impact analysis | Does the AI identify the known impacted Applications, Technologies, Vendors, Contracts, Capabilities, or Risks? |
| Semantic ID behavior | Does the AI resolve Noun Instances consistently across source inventories? |
| Rule interpretation | Does the AI apply the expected natural-language rules when mapping, inferring, validating, or explaining model content? |
| Dashboard / report output | Does the generated output match the intended audience, scope, structure, and evidence expectations? |
| Governance behavior | Does the runtime distinguish candidate, inferred, reviewed, approved, rejected, or stale model knowledge? |
Feedback should flow backward from the environments issues or ideas are identified in back to the Development environment where changes are implemented. UAT defects and enhancement requests should return to DEV for correction. Production defects, stale data signals, missing relationships, weak outputs, and new stakeholder requirements should also return to DEV. This creates a controlled improvement loop rather than allowing production users to become the first testers of unvalidated model behavior.
| Feedback Source | Examples | Typical Disposition |
|---|---|---|
| DEV feedback | Weak rules, missing attributes, poor Semantic IDs, failed graph compilation, disconnected nodes. | Correct in DEV and retest. |
| UAT feedback | Failed test scenarios, incorrect AI responses, weak impact-analysis paths, dashboard defects, unclear explanations. | Return to DEV, correct, recompile, and rerun UAT. |
| PROD feedback | Stale data, missing relationships, new business questions, production defects, enhancement requests. | Triage for DEV correction, UAT validation, or direct backlog prioritization. |
The three-environment pipeline model also helps clarify promotion discipline. Not every model change should move directly from DEV to PROD. Changes to the Taxonomy, Ontology, inventory mappings, Semantic ID rules, relationship inference rules, reification rules, prompts, dashboards, reports, or Shared Enterprise AI Runtime behavior may need validation before broad use.
| Change Type | Promotion Consideration |
|---|---|
| New Noun Type | Validate definition, inventory linkage, governance owner, and relationship implications. |
| Ontology rule change | Test whether AI interpretation, mapping, inference, and validation behavior changes as intended. |
| Inventory source change | Confirm source structure, attributes, freshness, access, and interpretation rules. |
| Semantic ID rule change | Validate identity resolution and avoid breaking existing references. |
| Relationship inference rule change | Test known relationship paths and false-positive behavior. |
| Reification rule change | Confirm that relationships are not being over-reified or under-reified. |
| Dashboard or report change | Validate audience fit, data freshness, role access, evidence, and presentation quality. |
| Runtime prompt or agent behavior change | Run prompt / response regression tests and stakeholder validation scenarios. |
For smaller or early-stage implementations, these environments do not need to be physically separate platforms. DEV, UAT, and PROD may begin as controlled folders, branches, versions, workspaces, access groups, or runtime configurations. As the model matures, the enterprise may decide to implement stronger separation through dedicated repositories, controlled deployments, automated testing pipelines, environment-specific agents, external graph stores, or production-grade runtime controls.
The practical principle is simple:
DEV builds and improves the model. UAT validates model behavior. PROD delivers governed model value. Feedback improves the next version.
Shared Enterprise AI Runtime is the broad delivery pattern
A Shared Enterprise AI Runtime is a governed AI delivery pattern in which the IF4IT EM is exposed through one or more AI-enabled runtime mechanisms so authorized stakeholders can query, analyze, traverse, visualize, and work against a common governed enterprise model.
The term is intentionally broader than any single implementation technology. A Shared Enterprise AI Runtime may be implemented with different deployment realization paradigms, such as but not limited to RAG, Agentic RAG, Graph-RAG, custom AI agents, custom GPT-style assistants, external graph runtimes, generated applications, dashboards, reports, or hybrid combinations of these patterns.
| Related AI / Runtime Term | Fit | How It Relates to the Shared Enterprise AI Runtime |
|---|---|---|
| RAG | Strong but incomplete | Retrieval-Augmented Generation can allow AI to retrieve IF4IT EM content and use it while answering questions. However, ordinary RAG does not necessarily imply graph traversal, agent behavior, governed model promotion, or multi-user operating discipline. |
| Agentic RAG | Very strong | Agentic RAG is a closer fit when the AI can plan, retrieve iteratively, use tools, navigate sources, reformulate questions, and perform multi-step reasoning over IF4IT EM content. |
| Graph-RAG / Graph-augmented RAG | Strong when graph-backed | Graph-RAG is a strong fit when the compiled IF4IT EM graph is used directly for retrieval, traversal, neighborhood expansion, relationship reasoning, dependency analysis, or path-based explanation. |
| Custom AI Agent | Strong | A custom agent can expose the IF4IT EM through a governed user experience, tool calls, workflow logic, role-specific prompts, and controlled access to model content. |
| Custom GPT-style Assistant | Strong as an implementation mechanism | A custom GPT-style assistant can package IF4IT EM content, instructions, rules, and expected behaviors for a bounded audience or use case. |
| Enterprise Knowledge Assistant | Strong business-facing term | This term is useful for stakeholders because it describes an AI assistant that answers questions over enterprise knowledge. It is less precise than Shared Enterprise AI Runtime because it may imply question answering only. |
| Knowledge Agent | Strong | A Knowledge Agent can use the IF4IT EM as its semantic substrate for retrieval, reasoning, summarization, analysis, and recommendation. |
| Tool-using Agent | Strong when tools are involved | Applies when the AI can query graph databases, search indexes, APIs, inventories, document stores, dashboards, ticketing systems, or workflow services. |
| External Graph Runtime | Strong when the graph is persistent | Applies when the IF4IT EM is compiled into an external graph or graph-compatible structure and accessed through graph queries, APIs, dashboards, or applications. |
| Generated Application Runtime | Strong when AI-generated apps are used | Applies when AI generates applications, dashboards, reports, or visualizations that operate over IF4IT EM graph outputs. |
| AI Chatbot | Too narrow | A chatbot may provide a conversational interface, but the IF4IT EM runtime pattern is broader than chat and includes graph traversal, analysis, governance, dashboards, generated outputs, and model improvement. |
The practical point is that the IF4IT EM does not require one specific AI delivery architecture. The same governed semantic model can be exposed through different runtime patterns as the enterprise matures.
NOTE: It is not the purpose of this document to detail each of the different runtime models. The reader should research what realization model is best for his/her enterprise, given the tools and technologies they’ve chosen to work with.
IMPORTANT NOTE: It is critically important to realize that every AI offering is somewhat different, having different levels of maturity and capabilities. When using AI technologies, the reader should thoroughly test how the developed model works with different AI offerings in order to identify and select one that works best for your own enterprise’s needs and tolerances. The IF4IT cannot predict or control how different AI models perform so your due diligence by your enterprise for selecting such tools is critical to ensure you can meet your end users’ needs.
The in-AI-memory graph supports model improvement
An in-AI-memory graph can be used by the modeler to improve the IF4IT EM before, during, and after broader delivery. This is one of the most important uses of AI in the IF4IT EM lifecycle.
When AI compiles the model into memory, the modeler can ask it to inspect the graph for issues, opportunities, and improvement candidates. These may include missing Noun Types, weak Noun Type definitions, inconsistent attributes, poor Semantic IDs, duplicate Noun Instances, incomplete inventories, missing relationships, weak relationship evidence, over-reified relationships, under-reified relationships, or unclear rules.
| Model Improvement Area | How AI Can Help |
|---|---|
| Inventory quality | Identify dirty, incomplete, duplicate, stale, inconsistent, fuzzy, or weakly described inventory data. |
| Attribute improvement | Recommend attribute cleanup, attribute mapping, missing attributes, better attribute names, or stronger attribute descriptions. |
| Semantic ID generation | Generate best-fit Semantic IDs where source identifiers are missing, unstable, ambiguous, or inconsistent. |
| Relationship inference | Suggest candidate relationships across Noun Instances and inventories. |
| Reified relationship discovery | Identify relationships that may deserve to become first-class semantic constructs. |
| Rule improvement | Recommend new or improved natural-language rules for interpretation, mapping, validation, inference, and output generation. |
| Ontology improvement | Identify weak definitions, duplicate terms, missing aliases, unclear semantic boundaries, or poorly explained Noun Types. |
| Taxonomy improvement | Identify candidate Noun Types, excessive overlap, specialization opportunities, or unnecessary complexity. |
| Graph quality | Identify disconnected nodes, weakly connected domains, missing paths, surprising dependencies, or inconsistent relationship structures. |
| Governance readiness | Identify suggestions that require evidence, validation, Inventory Owner review, or stakeholder disposition. |
AI-generated improvement suggestions should not automatically become trusted model truth or source-inventory truth. They are candidates. The modeler, Inventory Owners, Ontology Stewards, governance leads, and affected stakeholders decide which suggestions should be accepted, rejected, revised, deferred, or routed for further review.
Shared runtime delivery patterns determine how stakeholders consume the model
Once the IF4IT EM has been compiled, generated, packaged, or connected to a runtime, it can be delivered to broader enterprise audiences. Delivery is how the model reaches users. Utilization is what users do with it.
Different enterprises may choose different delivery patterns depending on their maturity, security needs, tooling environment, audience, cost tolerance, and operational goals.
| Delivery Pattern | Description | Example Use |
|---|---|---|
| Direct AI session | Users interact with AI directly after model content has been loaded or connected. | Early exploration, modeler analysis, controlled pilots. |
| Private modeler workspace | Modelers use AI privately to inspect and improve the IF4IT EM. | Ontology refinement, inventory cleanup, relationship validation. |
| Custom AI agent or GPT | The enterprise packages the model into a reusable AI experience. | Enterprise Q&A, architecture assistant, governance assistant, portfolio assistant. |
| AI RAG pattern | The model becomes part of a retrieval layer that AI uses to answer questions or guide reasoning. | Controlled semantic search, policy-aware retrieval, assisted analysis. |
| Agentic RAG pattern | AI retrieves, reasons, plans, uses tools, and performs multi-step work against IF4IT EM content and connected sources. | Guided analysis, iterative dependency discovery, governance triage, multi-step impact analysis. |
| Graph-RAG pattern | AI uses graph structure, graph neighborhoods, paths, and relationships as part of retrieval and reasoning. | Nth-degree dependency analysis, relationship-aware search, path explanation, graph-based inference. |
| External graph runtime | The graph is loaded into a graph database, ontology platform, document store, or other runtime. | Graph queries, persistent graph analysis, integration with enterprise platforms. |
| Generated application runtime | AI generates applications, dashboards, visualizations, reports, or user interfaces that operate over graph outputs. | Executive dashboards, operational reports, dependency views, impact-analysis tools. |
| Hybrid runtime | AI combines in-memory reasoning, retrieved content, external graph queries, generated interfaces, and deterministic services. | Mature enterprise AI operating environment. |
The delivery pattern should be intentional. A modeler’s private AI session may be appropriate for exploration and model improvement. A Shared Enterprise AI Runtime requires stronger controls around access, scope, privacy, data freshness, evidence, explainability, performance, cost, and user experience.
Again, It is not the purpose of this document to detail each of the different runtime models. The reader should research what realization model is best for his/her enterprise, given the tools and technologies they’ve chosen to work with.
Again, It is critically important to realize that every AI offering is somewhat different, having different levels of maturity and capabilities. When using AI technologies, the reader should thoroughly test how the developed model works with different AI offerings in order to identify and select one that works best for your own enterprise’s needs and tolerances. The IF4IT cannot predict or control how different AI models perform so your due diligence by your enterprise for selecting such tools is critical to ensure you can meet your end users’ needs.
AI runtime generates interactive visual knowledge constructs
Figure: On-demand, AI-synthesized, interactive, visual knowledge constructs.
Once the model is constructed in AI memory, AI itself can also become the model’s user interface. Based on nothing but prompts, the right AI agents can make it easier to search for and find, traverse, query, visualize, analyze, reason, make decisions, and far more… all based on the synthesized graph.
AI’s generative capabilities allow knowledgeable users to synthesize both simple and complex high-value knowledge constructs that include but are not limited to interactive, context-specific visualizations from the graph (e.g., reports, dashboards with charts & graphs, schematic diagrams, data flow diagrams, dependency diagrams, dynamic trees, heatmaps, and anything you can imagine).
Advanced users can use AI’s code generation features to create and deploy fixed applications that act as user interfaces, complete with intuitive user experiences, that sit over the graph.
AI runtime utilization turns the model into enterprise value
AI runtime utilization is where the IF4IT EM begins producing visible value for stakeholders. Once AI has compiled or received a graph representation of the model, users can ask questions, explore dependencies, generate outputs, compare scenarios, inspect risks, analyze gaps, and support decisions.
Utilization patterns include, but are not limited to:
| Utilization Category (a.k.a. Use Cases) | Examples |
|---|---|
| Semantic search and question answering | Ask what exists, what something means, who owns it, where it is used, what it depends on, or what it impacts. |
| Impact analysis | Identify what may be affected by changing an Application, Technology, Vendor, Contract, Data Store, Capability, Policy, or Process. |
| Dependency analysis | Traverse upstream and downstream relationships across systems, vendors, contracts, data, technologies, and capabilities. |
| Gap analysis | Identify missing inventories, missing attributes, missing relationships, disconnected Noun Instances, or weak coverage. |
| Portfolio analysis | Compare Applications, Technologies, Vendors, Contracts, Risks, Costs, Capabilities, and modernization candidates. |
| Risk and governance analysis | Identify risky dependencies, weak ownership, expiring contracts, unsupported technologies, policy gaps, or governance exceptions. |
| Graph traversal and exploration | Move from one Noun Instance to related Noun Instances across multiple degrees of separation. |
| Graph comparison | Compare current state to future state, one snapshot to another snapshot, or one domain model to another. |
| Dashboard and report generation | Generate executive summaries, operational views, model-health views, dependency dashboards, and governance reports. |
| Visualization generation | Produce diagrams, trees, graphs, maps, matrices, and interactive visualizations from model structure. |
| Generated application support | Generate applications or interfaces that operate over model outputs for end users. |
| Decision support | Support roadmap planning, modernization choices, investment decisions, rationalization, sourcing, governance, and operational prioritization. |
The same compiled graph can serve different audiences. A technology leader may use it to understand application rationalization. A risk leader may use it to identify weak controls. A procurement leader may use it to understand vendor and contract exposure. A product owner may use it to understand dependency chains. A governance team may use it to identify missing ownership or weak evidence. A modeler may use it to improve the model itself.
Modeler utilization and stakeholder utilization are different
The modeler and the stakeholder both use the IF4IT EM, but they usually use it for different reasons.
The modeler uses AI to improve the model. Stakeholders use AI to consume the model. Both depend on the same governed semantic foundation.
| User Type | Primary Use | Examples |
|---|---|---|
| Modeler | Improve, test, validate, and govern the IF4IT EM. | Inspect graph quality, identify missing Noun Types, improve Ontology rules, clean inventory data, generate Semantic IDs, infer candidate relationships, validate reified relationships. |
| Ontology Steward | Maintain semantic quality and rule discipline. | Refine definitions, manage aliases, improve relationship rules, resolve semantic ambiguity, govern Noun Type changes. |
| Inventory Owner | Improve source inventory quality and accountability. | Review AI-suggested source corrections, missing attributes, duplicate records, stale records, and better descriptions. |
| Governance Lead | Control trust, evidence, and promotion. | Review AI-generated suggestions, assign disposition, require evidence, track provenance, approve or reject model changes. |
| End-user stakeholder | Consume model knowledge for business or operational work. | Ask questions, run impact analysis, inspect dependencies, review dashboards, generate reports, support decisions. |
| Executive Sponsor | Use model outputs to guide investment and strategy. | Review portfolio insights, risk exposure, modernization opportunities, dependency summaries, and governance maturity. |
This distinction should be designed into the runtime. Modelers need access to exploratory outputs, candidate suggestions, raw issues, validation details, and improvement recommendations. Stakeholders need trusted answers, governed views, role-appropriate dashboards, understandable explanations, and clear evidence.
A Shared Enterprise AI Runtime should not expose every modeler-facing candidate suggestion as if it were trusted enterprise truth. Conversely, a private modeler workspace should not be limited to polished stakeholder views when the modeler needs to inspect the messy reality of the model.
Runtime outputs require evidence, confidence, and human review
AI runtime outputs can be useful without being automatically authoritative. A compiled graph can expose patterns, relationships, gaps, risks, and recommendations, but generated outputs still require evidence, confidence, provenance, and review discipline.
This is especially important when AI infers relationships, generates Semantic IDs, recommends data corrections, proposes reified semantic relationships, or produces decision-support outputs.
| Output Type | Review Need |
|---|---|
| Candidate relationship | Validate source evidence, relationship meaning, confidence, and business relevance. |
| Reified semantic relationship | Confirm that the relationship deserves first-class treatment and has meaningful attributes, lifecycle, governance, and evidence needs. |
| Inventory data improvement | Route to the Inventory Owner for review before source changes are made. |
| Attribute mapping | Confirm semantic fit and avoid misleading source-to-model translations. |
| Semantic ID | Validate uniqueness, stability, readability, and identity-resolution assumptions. |
| Dashboard or report | Confirm audience, scope, freshness, role access, interpretation, and evidence quality. |
| Impact analysis | Validate graph completeness, relationship direction, dependency assumptions, and confidence. |
| Decision recommendation | Require accountable review before acting on AI-generated conclusions. |
A good runtime should help users understand whether an output is candidate, inferred, reviewed, approved, rejected, stale, incomplete, or promoted into trusted model truth. The more important the decision, the more important the evidence and review path.
AI can propose, synthesize, and explain. Accountable owners decide what becomes trusted.
Use Trust Levels to Qualify AI Runtime Outputs
AI runtime outputs should not be treated as uniformly trusted or uniformly untrusted. Trust is graduated. An AI-generated answer, graph traversal, relationship inference, Semantic ID, dashboard, report, impact analysis, or recommendation may be useful at one level of maturity and inappropriate at another.
This is especially important for the IF4IT Enterprise Model because AI can operate against partially complete inventories, evolving ontology rules, inferred relationships, imperfect identifiers, and model content that is still being improved. The fact that AI can compile and reason over the IF4IT EM does not mean every compiled graph, generated output, inferred relationship, or recommendation should immediately be treated as authoritative.
Bad input data yields poor model outputs and lower trust. Better input data yields better model outputs and higher trust. Governed, evidence-backed, validated model knowledge yields the highest trust.
Trust levels give modelers, stakeholders, and governance participants a shared way to qualify AI runtime outputs.
| Trust Level | Label | Meaning | Typical Use |
|---|---|---|---|
| 0 | Unassessed | The content exists, but it has not been reviewed for quality, completeness, evidence, provenance, or runtime reliability. | Raw inventory ingestion, first-pass compilation, early model loading, initial discovery. |
| 1 | Exploratory | AI has interpreted, mapped, inferred, summarized, or generated an output, but the result remains experimental. | Private modeler workspace, discovery, graph exploration, early analysis. |
| 2 | Candidate | The output appears useful and may have supporting evidence, but has not yet been validated by accountable humans. | Candidate relationships, proposed Semantic IDs, suggested inventory improvements, draft graph outputs. |
| 3 | Evidence-Backed | The output is supported by source records, provenance, rules, repeated graph traversal, or other reviewable evidence. | Relationship validation, impact-analysis review, model-improvement queues, UAT scenarios. |
| 4 | Reviewed | A modeler, Ontology Steward, Inventory Owner, subject-matter expert, governance lead, or other accountable reviewer has reviewed the output. | Controlled stakeholder review, UAT promotion decisions, pre-production validation. |
| 5 | Approved / Trusted | The output has been accepted as trusted model truth or approved source-inventory truth through the appropriate governance path. | Production runtime, stakeholder-facing dashboards, decision-support outputs, governed reports. |
Trust levels should not be interpreted as a rigid universal scoring system. They are a practical operating vocabulary. The enterprise may choose to implement them as labels, metadata, workflow states, confidence indicators, review statuses, quality gates, or dashboard filters.
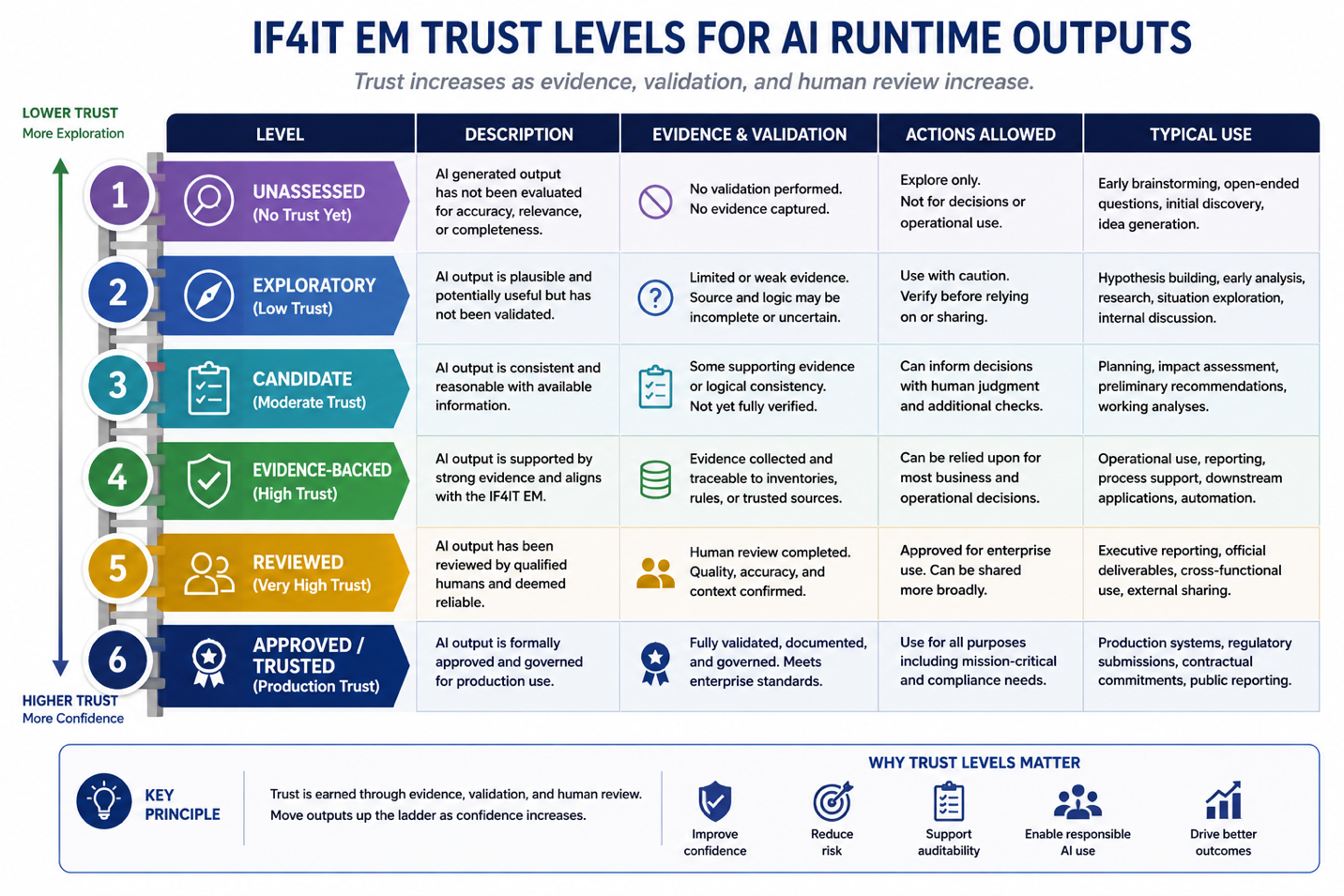
Figure: The IF4IT Enterprise Model Trust Ladder is a framework for communicating and helping to understand EM trust levels.
Several factors can raise or lower the trust level of AI runtime outputs.
| Trust Factor | Raises Trust When… | Lowers Trust When… |
|---|---|---|
| Inventory quality | Source inventories are complete, current, governed, and owned. | Inventories are stale, duplicated, incomplete, ambiguous, or poorly owned. |
| Ontology quality | Noun Types, definitions, attributes, rules, and relationships are clear. | Meanings are vague, rules conflict, aliases are unmanaged, or boundaries are unclear. |
| Semantic ID quality | Noun Instances can be identified consistently across sources. | Identifiers are missing, unstable, duplicated, opaque, or inconsistently mapped. |
| Evidence and provenance | Outputs can be traced to source records, rules, relationships, or graph paths. | Outputs lack source evidence, lineage, or explanation. |
| Relationship validation | Relationships have been reviewed, supported, and promoted appropriately. | Relationships are inferred but unreviewed, weakly supported, or directionally ambiguous. |
| Rule clarity | Natural-language or formal rules guide interpretation, inference, validation, and use. | Rules are missing, contradictory, overly broad, or too vague to guide AI behavior. |
| Human review | Accountable reviewers have validated outputs for the intended use. | Outputs bypass modelers, Inventory Owners, subject-matter experts, or governance leads. |
| Runtime controls | Access, freshness, scope, role, and output limitations are controlled. | Users receive stale, unrestricted, out-of-scope, or unexplained outputs. |
Trust levels should also influence how outputs are exposed in the runtime. A private modeler workspace can expose exploratory and candidate outputs because modelers need to see weak spots, uncertain relationships, and improvement opportunities. A Shared Enterprise AI Runtime should be more selective, especially when outputs influence business decisions, governance actions, investment choices, risk interpretation, or operational behavior.
| Runtime Context | Appropriate Trust Posture |
|---|---|
| Private modeler workspace | May expose unassessed, exploratory, candidate, evidence-backed, reviewed, and approved outputs, provided the modeler understands their status. |
| DEV model environment | May expose lower-trust outputs for testing, inspection, cleanup, and improvement. |
| UAT model environment | Should focus on candidate, evidence-backed, and reviewed outputs that can be validated through manual and automated testing. |
| Production runtime | Should favor reviewed and approved / trusted outputs, with clear labeling when lower-trust content is intentionally exposed. |
| Executive or stakeholder dashboard | Should expose only outputs appropriate for the audience, with provenance, freshness, confidence, or review status where needed. |
| Decision-support workflow | Should require evidence, review, and appropriate trust level before recommendations are acted upon. |
Trust levels also help distinguish model truth from source-inventory truth. A relationship inferred by AI may become trusted model truth after model governance review, but that does not automatically change the source inventory. A source-data correction suggested by AI may be useful, but it does not become source-inventory truth until the Inventory Owner or accountable source owner accepts it.
| Knowledge Type | Trust Question |
|---|---|
| Model-layer relationship | Has the relationship been reviewed, evidenced, and promoted into trusted model truth? |
| Reified semantic relationship | Has the relationship been validated as important enough to become a first-class semantic construct? |
| Source inventory value | Has the Inventory Owner accepted the change into the authoritative source? |
| Semantic ID | Has identity resolution been validated for stability, uniqueness, and usefulness? |
| AI-generated output | Is the output supported by evidence, rules, graph traversal, and appropriate review for its intended use? |
The practical goal is not to prevent early use. Early use is how many model defects, inventory defects, relationship gaps, and rule weaknesses are discovered. The goal is to prevent immature outputs from being mistaken for approved enterprise knowledge.
A modeler may use low-trust outputs to find problems. A stakeholder may need high-trust outputs to make decisions. A governance process should help the enterprise move useful knowledge from exploratory to trusted without pretending that every AI-generated output deserves the same level of confidence.
The more complete, current, well-defined, evidence-backed, and governed the IF4IT EM is, the more trustworthy its AI-generated outputs can become.
Best Practice
Treat AI compilation and AI runtime utilization as related but distinct operating patterns.
First, ensure that AI can ingest the IF4IT EM’s Taxonomy, Ontology, Inventories, rules, attributes, Semantic IDs, and relationships to compile a working graph. Then decide how that graph will be delivered and used — through private modeler workspaces, direct AI sessions, Shared Enterprise AI Runtimes, custom AI agents, RAG, Agentic RAG, Graph-RAG, external graph runtimes, generated applications, dashboards, reports, or hybrid runtime patterns.
Do not treat AI compilation as the end goal. Compilation creates the working graph. Runtime utilization creates the enterprise value. Both must be governed.
Implementation Guidance
When using AI as the Graph Compiler and Runtime, modelers should:
| Step | Guidance |
|---|---|
| 1. Define the intended use | Decide whether the immediate goal is private modeler improvement, stakeholder delivery through a Shared Enterprise AI Runtime, or both. |
| 2. Prepare the source artifacts | Ensure the Taxonomy, Ontology, Inventories, rules, attributes, Semantic IDs, and relationships are available to AI. |
| 3. Define the compilation scope | Decide which Noun Types, inventories, domains, timeframes, or use cases are included. |
| 4. Compile the graph | Allow AI to build an in-AI-memory graph or generate an externally reified graph output. |
| 5. Inspect the graph | Ask AI to identify gaps, weak relationships, missing attributes, duplicate records, poor identifiers, and disconnected structures. |
| 6. Validate candidate outputs | Review AI-generated mappings, relationships, identifiers, and recommendations before promotion. |
| 7. Choose the delivery pattern | Decide whether the model will be delivered through a private workspace, custom agent, RAG pattern, Agentic RAG, Graph-RAG, external runtime, generated application, dashboard, or hybrid runtime. |
| 8. Define utilization use cases | Identify the questions, analyses, dashboards, workflows, or decisions the runtime should support. |
| 9. Apply governance controls | Establish access, evidence, confidence, provenance, review, and promotion rules. |
| 10. Pilot with real users | Test both modeler-facing and stakeholder-facing use cases. |
| 11. Capture feedback | Use runtime activity to identify model, inventory, rule, relationship, and output improvements. |
| 12. Improve and refresh | Feed approved improvements back into the governed IF4IT EM and repeat the refresh cycle. |
Benefits
Using AI as both the Graph Compiler and Runtime creates several benefits.
| Benefit | Explanation |
|---|---|
| Faster enterprise understanding | AI can rapidly assemble and reason over connected enterprise knowledge. |
| Improved model quality | Modelers can use AI to identify gaps, inconsistencies, weak descriptions, missing relationships, and poor identifiers. |
| Better stakeholder access | Shared runtimes can expose the model through agents, dashboards, reports, applications, or other consumable experiences. |
| Reusable semantic substrate | The same governed model can support many use cases instead of repeated one-off analysis. |
| Stronger impact analysis | Graph traversal helps identify upstream, downstream, and cross-domain impacts. |
| Better inventory improvement | AI can suggest source-data improvements while preserving Inventory Owner accountability. |
| More flexible delivery | Enterprises can choose private, shared, external, generated, or hybrid runtime patterns. |
| Scalable value creation | The IF4IT EM can support more users and more use cases as the model matures. |
| Stronger governance | Evidence, confidence, provenance, and review can be built into model use. |
| Better fit for enterprise adoption | A Shared Enterprise AI Runtime gives authorized stakeholders a common way to work against the same governed model. |
Common Mistakes
The reader should be aware of the following common mistakes…
| Mistake | Why It Is a Problem | Better Pattern |
|---|---|---|
| Confusing compilation with runtime use | A compiled graph is only useful if people or systems can use it effectively. | Treat compilation and utilization as distinct operating patterns. |
| Treating AI output as automatically true | AI may infer plausible but incorrect relationships or recommendations. | Require evidence, confidence, provenance, and human review. |
| Loading inventories without Ontology context | AI may misinterpret fields, meanings, relationships, and source assumptions. | Provide Noun Type definitions, rules, attributes, mappings, and inventory-processing guidance. |
| Treating a private modeler session as a Shared Enterprise AI Runtime | Private sessions are useful but usually not governed for broad simultaneous use. | Package shared runtimes with access, refresh, evidence, and user-experience controls. |
| Exposing candidate model improvements as trusted stakeholder outputs | Experimental suggestions may be mistaken for approved enterprise knowledge. | Separate candidate, inferred, reviewed, and approved model knowledge. |
| Assuming RAG alone is the whole runtime | RAG is useful, but it may not provide graph traversal, tool use, role-specific governance, or model improvement workflows by itself. | Use RAG, Agentic RAG, Graph-RAG, agents, graph runtimes, generated apps, or hybrid patterns according to the need. |
| Ignoring delivery design | Users may not know how to consume or trust the model. | Design delivery patterns intentionally for the intended audience. |
| Failing to distinguish modeler and stakeholder use | Modelers need exploratory detail; stakeholders need governed, role-appropriate outputs. | Design different runtime experiences for different user classes. |
| Skipping refresh discipline | Runtime outputs may become stale if source inventories change. | Align runtime use with refresh cycles, source ownership, and governance cadence. |
Closing Perspective
AI compilation turns the IF4IT EM into a working graph that you can couple with your chosen and vetted AI tools. AI runtime utilization turns that graph into a foundation for enterprise understanding, model improvement, decision support, and generated outputs.
The IF4IT EM is most powerful when AI is used in both ways (i.e., a graph compiler/synthesizer and a runtime). In a private modeler workspace, AI helps the modeler inspect, test, improve, and govern the model. In a Shared Enterprise AI Runtime, AI helps stakeholders consume the governed model for day-to-day business activities, analysis, and decisions.
The operating pattern is simple:
Compile the model. Deliver the graph. Use the runtime. Capture feedback. Govern improvements. Refresh the source model. Repeat.
Copyright for the International Foundation for Information Technology (IF4IT): 2008 - Present
Legal Disclaimers